Structure-aware Fisheye Views for Efficient Large Graph Exploration
作者:panjiacheng 日期:2018 年 9 月 11 日
没有评论
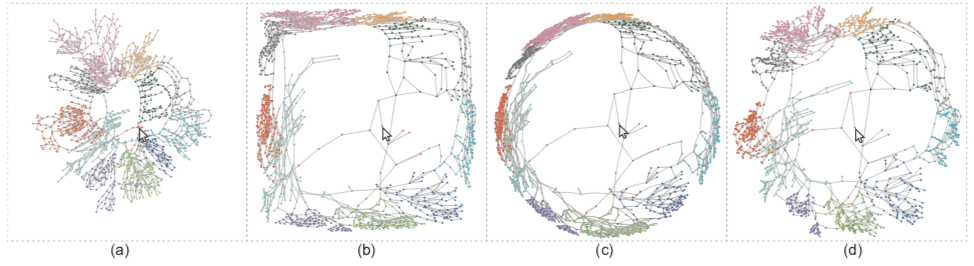
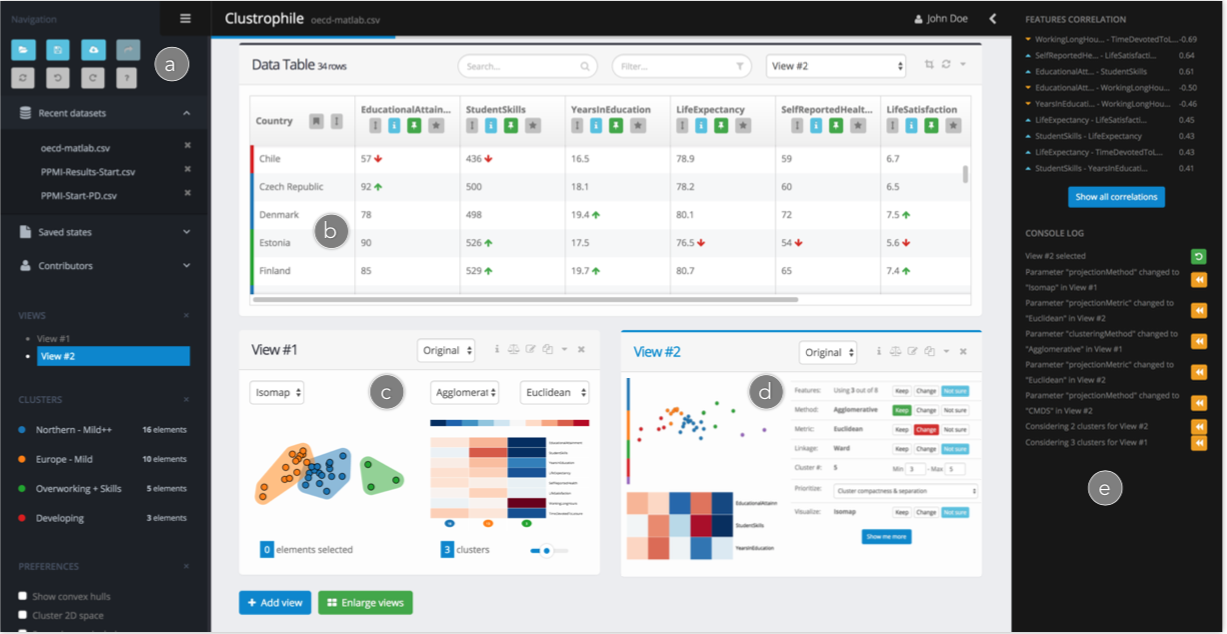
左侧边栏可以导入数据,或者打开以及前保存的结果。右侧显示了所有的日志,可以轻松回到之前的状态,视图的主区域上半部分是数据,下半部分是聚类视图。
数据聚类对于处理无标签数据,高维数据是非常有效的工具。聚类算法中如何确定最好的聚类方法和参数比较困难,需要可视化系统的帮助。Clustrophile 2,这是一种用于引导聚类分析的新型交互式工具,引导用户进行基于聚类的探索性分析,调整用户反馈以改进聚类效果,并帮助快速推理群集之间的差异。为此,Clustrophile 2提供了一个新颖的功能,clustering tour,帮助用户选择聚类参数,并评估与当前分析目标和用户期望的差距。我们通过12位数据科学家的user study评估这个系统。结果表明,Clustrophile 2提高了专家和非专家的探索性聚类分析的速度和有效性。
论文:Investigating the Effect of the Multiple Comparisons Problem in Visual Analysis
发表:CHI’ 18
作者:Emanuel Zgraggen, Zheguang Zhao, Robert Zeleznik, Tim Kraska
继续阅读 =>
作者:Le Liu, Alexander P. Boone, Ian T. Ruginski, Lace Padilla, Mary Hegarty, Sarah H. Creem-Regehr, William B. Thompson, Cem Yuksel, and Donald H. House
发表:2017 InfoVis
一、介绍
1. 背景
模拟模型已成为预测生成的主要工具,但这些模型的预测通常包含高度不确定性。这种不确定性可能有很多来源。当被建模的系统由非线性动力学控制时,而且敏感地依赖于初始和边界条件,这是不确定性就会不可避免的发生。其他不确定性来源包括对实际系统建模,参数估计和数值误差累积所做的假设和近似。
集合(Ensemble)是对可能由包含不确定性的模型产生的投影空间进行采样的关键工具之一。在天气预报中使用模型就是一个很好的例子。通常,一次或多次天气模型多次运行,每次运行的初始条件或参数略有不同。这就得到了基于模型的单个投影的集合,气象学家必须从中确定要向公众呈现的聚合预测。通常,这将包括预测的天气结果,以及预测的确定性或置信度的度量。
2. 挑战
虽然集合是进行预测的重要工具,但是它们很难用于创建有效的可视化。 继续阅读 =>
作者:Fritz Lekschas, Benjamin Bach, Peter Kerpedjiev, Nils Gehlenborg, and Hanspeter Pfister
2017 InfoVis
一、简介
1)目标:辅助用户在巨大的矩阵(百万*百万级)中探索众多感兴趣的区域
2)挑战:
3)贡献 (HiPiler ):
作者:Yunhai Wang, Xiaowei Chu, Chen Bao, Lifeng Zhu, Oliver Deussen, Baoquan Chen and Michael Sedlmair
发表:2017 infoVis
一、简介
现有的Wordle,存在不一致性的问题,即在词云的调整过程中,会将摆放不正确的单词单纯地移动到其他空白区域,这样有可能导致全局大量单词需要改变,最后导致词云结果不尽如人意。
为了保持词云的一致性,合适的编辑改变方式变得更加重要。并且每个单词的临近单词都应该被考虑,因为它们之间可能有着重要的意义。为此本篇文章提出了一个名为EdWordle的工具,这个工具主要用到了一个使得词云局部和全局上下文感知交互技术。
该工具是一个编辑词云的工具,在编辑词云的过程中,单词之间的邻里关系可以得到很好的保留,并且有着很好的紧凑性,可以用于编辑词云、提升现有词云并作为一个创作工具使用。
作者:Gennady Andrienko, Natalia Andrienko, Georg Fuchs, and Jose Manuel Cordero Garci
发表:2017 VAST
一、简介
针对不同的分析任务,研究人员会对轨迹中的不同部分感兴趣,例如在研究起飞、降落计划时,只有轨迹中的起始与结束阶段是有用的。对数据中与与分析任务有关的部分进行聚类,叫做相关聚类(Relevance-aware Clustering)。一般情况下,相关聚类只需要提前把数据处理好,过滤掉数据中的无关部分,存储处理好的数据即可,但是在分析过程中对相关与不相关的判断会不断发生变化。因此,本文针对轨迹的相关聚类,提出了一套完整的工作流程与分析方法。文章所用的数据集为飞行轨迹数据,但文章提出的方法适用于其他所有类型的轨迹。 继续阅读 =>
作者:Dominik Moritz, Danyel Fisher, Bolin Ding, Chi Wang
发表:2017 CHI
一、简介:
探索式数据分析可以理解为一个分析多维数据的过程,主要通过探索数据分布及不同维度之间关联关系来完成分析过程。在这个过程中,最重要的两个要素是迭代探索与探索速度。近似查询(Approximate Query)是在探索式数据分析中常用的查询方法,能够在交互级别的响应时间内建立一个基于近似的可视化结果,但查询结果往往具有不确定性。本文提出了乐观可视化(Optimistic Visualization)的概念方法,并通过实验验证了其有效性。
作者:Younghoon Kim, Kanit Wongsuphasawat, Jessica Hullman, Jeffrey Heer
发表:2017 CHI (Best paper honorable mention)
简介 在实际使用时,用户可能会有连续查看多个图表的需求,然而已有的推荐系统只关注单一图表。本文的作者考虑可视化之间的相似性和顺序,给出了GraphScape——一个可以结合顺序评估变换成本的有向图模型。
