DQNViz: A Visual Analytics Approach to Understand Deep Q-Networks
作者:Junpeng Wang, Liang Gou, Han-Wei Shen, and Hao Yang
发表:VAST 2018 (honorable mention)
一、简介
Deep Q-Network (DQN)是Google DeepMind研发的用于解决强化学习问题的深度卷积神经网络,用于训练一个能自动玩Atari 2600游戏的代理。其目的让代理跟环境(游戏)进行交互,代理需要进行游戏内的操作,完成操作后,根据某种奖励机制,不同游戏状态会获得不同的奖励,DQN的最终目标是使整个训练过程的全部奖励之和达到最大。下图为不断循环的训练过程: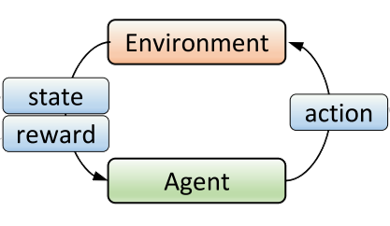
训练结束后将得到一个事件序列,包括状态(r)、操作(a)、奖励(r):
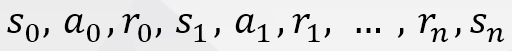
DQN的最终目标则是使得整体奖励最大化:
然而,跟监督、非监督的机器学习使用固定的数据集训练不同,强化学习的训练数据是被训练的代理的经验,是在训练过程中逐渐生成的,需要对其进行动态总结来理解数据。同时,我们又如何解释代理进行某些操作的行为?如何调整训练过程中的随机操作的比例?目前仍然缺乏一个面向强化学习模型的可视分析工具。
本文的贡献在于:
a.操作 b.奖励 c.游戏屏幕(值域为[0,255]的84*84矩阵) d.生命 e.是否终止 f.是否随机 g.当前步的预测Q值 h.当前步的目标Q值
3.4数据的层次关系
步 (Step):包含八种数据的训练步
段 (Segment):某个长度的一串连续的Step
集 (Episode):游戏开始到结束的所有Step
轮 (Epoch):一轮的所有训练步,共25,000步
四、可视分析系统
DQNvis的系统是一个自顶向下探索的系统,如图:
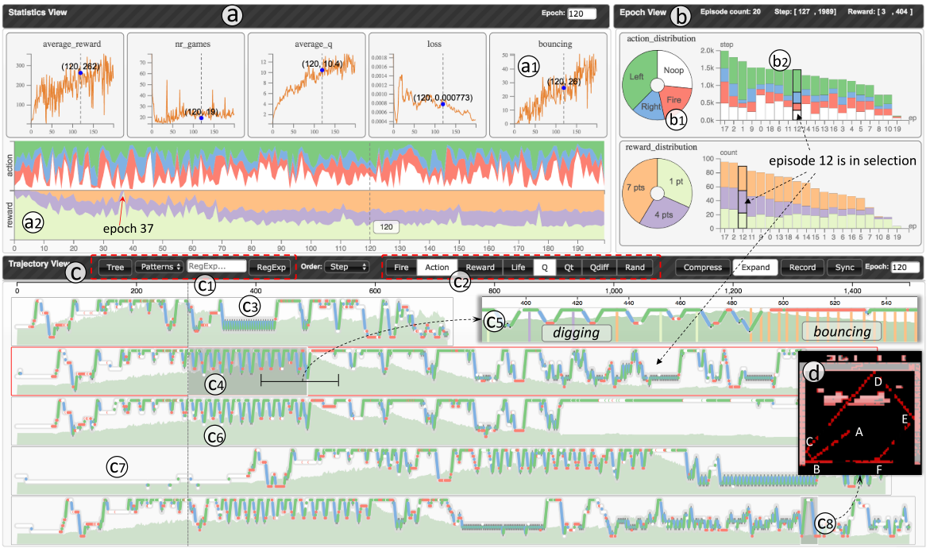
系统共分为四个视图。
Statistics View(左上):用于展示训练过程中的统计值变化(上半部分)与不同的操作、奖励在各轮中占得比重(下半部分),每张图的横轴均表示轮数(epoch)。
Epoch View(右上):在Statistics View中选中某一轮后,epoch view会显示该轮所有episode中的操作(上)与奖励(下)分布。
Trajectory View(下方): 横轴为训练步数,纵轴轴从下往上表示游戏屏幕中从左到右的顺序,因此折线可以表示代理在游戏中的运动轨迹,不同的操作用不同颜色点叠加在折线上,背景的颜色填充表示DQN预测Q值或目标Q值的变化,折线上的矩形长条颜色高亮表示获得的奖励。
同时,在Trajectory View中,将每集 (Episode) 划分为长度100的段 (Segment),使用DTW计算一轮内 (Epoch) 所有段之间的相似性,并用层次聚类找到相似的模式。此外,也可通过用正则表达式定义模式,在数据中进行搜索。
Segment View(下图):一个segment包含游戏屏幕的许多帧,每一帧屏幕是一个84*84的矩阵,每四个连续帧为一个状态。DQN共5层(三个卷积层,两个全连接层),整个网络中共160个filter。提取每个filter中被最大化激活的状态,并计算该状态屏幕中每个像素点的显著性(也有被激活的与没被激活的像素点之分)。左侧柱状图表示每个filter激活的像素点数目,中间PCA投影使用每个filter的被激活状态的显著性矩阵计算,点的大小表示激活的像素数目,右侧的四个屏幕选择某种聚合方式,将一个segment中所有状态的像素激活情况表示。
五、案例
这里介绍一个通过使用DQNvis系统调整随机操作比例的案例。
实验一:专家认为训练完200轮以后的代理应该比随机操作强,因此不需要随机操作。得到的测试结果分为三阶段。一阶段正常,但是二阶段中代理未学习到要发球的知识,因此一直拿球未发,导致游戏在三阶段因为长时间而崩溃,如图。

实验二:通过实验一,专家认识到训练过程中是需要随机操作的,尤其是在代理反复重复相同操作模式但无奖励时。因此缓存了20步的训练数据,并在缓存中使用正则表达式搜索重复3次及以上的操作模式,在搜索到的这种结果后增加随机操作。得到的训练结果如图,也是分为三阶段,一阶段正常,二阶段仍重复一个相同的模式,但是模式长度较长,完成一次需50步,因为在二阶段不断重复一个模式过长,游戏最终也在三阶段崩溃了。

实验三:根据实验1与2,专家对算法进行优化,将缓存长度变为100,搜索的模式为重复2次及的模式,得到的最后结果中,随机操作实际占2%,小于预定的5%。
六、专家访谈
在访谈中,所有专家都认为系统非常好用,但也提出了一些建议: