DropoutSeer: Visualizing Learning Patterns in Massive Open Online Courses for Dropout Reasoning and Prediction
论文:DropoutSeer: Visualizing Learning Patterns in Massive Open Online Courses for Dropout Reasoning and Prediction
作者:Yuanzhe Chen, Qing Chen, Mingqiao Zhao, Sebastien Boyer, Kalyan Veeramachaneni, Huamin Qu
发表: 2016 VAST Conference track
1 简介
MOOCs全称Massive Open Online Courses,即大型网络公开课。MOOCs自2012年出现起迅速发展。然而,在迅猛发展背后,MOOCs也存在着许多问题,其中最主要的问题就是高居不下的退学率。本文提出了一种可视化分析系统——DropoutSeer,该系统不仅能够帮助MOOCs的讲师和教育人员了解学生退学行为和原因,还可以帮助机器学习的研究人员确定退学行为预测模型中特征,进一步提高模型的表现。
2 数据说明
本文中所用到的数据来源于Coursera和edX提供的JAVA和NCH课程数据(数据内容见图1)。其中点击事件数据中记录了用户的播放、暂停和搜索等行为;作业提交数据记录用户提交作业的情况以及得分;论坛发帖数据则记录了用户在课程论坛上的发帖情况。
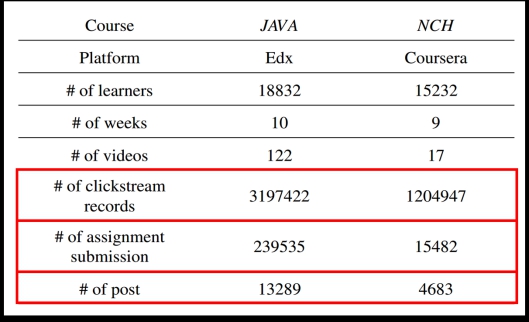
图1 数据内容
3 系统设计
3.1 任务分析
本文作者在和用户进行了三轮访谈之后,总结出了以下系统需要完成的任务:
- T1. 退学行为的大致分布如何?
- T2. 对于退学的同学,是否能被分组?是什么因素影响了分组原因?
- T3. 不同的学生分组能够证明什么样的学习模式?
- T4. 选择的学生组和论坛帖子之间有没有关联?
- T5. 特定的学生的学习模式是什么样的?
3.2 预测模型
在执行预测模型前,作者首先对“退学”做出了明确定义,即如果某同学在w周没有留下任何数据,则说明该同学在w周退学了。
作者从数据中抽取出特征向量(见图2)后,分别采用了以下三种分类模型对数据进行测试,他们分别是:
- 逻辑斯特回归模型(Logistics Regression);
- 随机森林模型(Random Forest);
- 最邻近模型(Nearest-neighbors);
随后,通过交叉验证优化模型,根据交叉验证选择表现最好的模型进行似然估计。
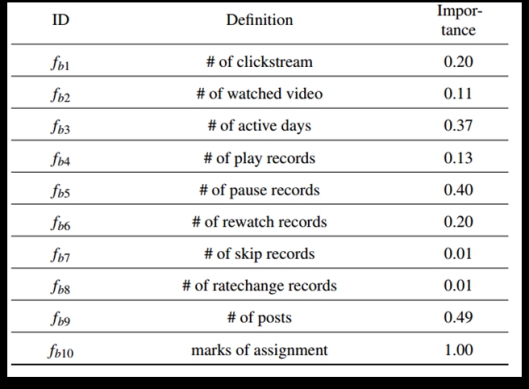
图2 特征向量
3.3 聚类方法
本文采用了一种基于密度的聚类方法,在经过预测的学生分组内进行聚类,分别形成了不同的子组,具体步骤如下:
- 选取特征向量
- MDS降维
- DBSCAN聚类
这里选取的特征向量与预测模型中的特征向量相同(见图2);
将高维向量降维到二维,用散点图的进行表示。其中,因为Cosine距离对极端值更为敏感,所以在测量向量之间的距离时,采用了这种测量方法;
DBSCAN算法时间消耗小,因此更适合本文系统对聚类结果进行实时更新。
3.4 视觉编码
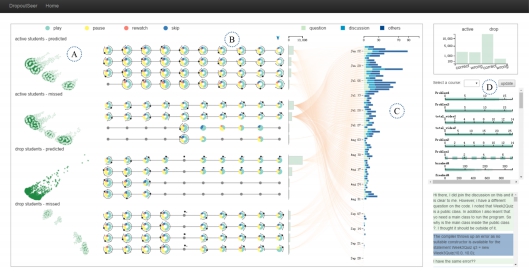
图3 系统整体界面
3.4.1 聚类视图
聚类视图反映的是预测和聚类的结果(见图3 A区域)。预测模型将学生分为了四组,他们分别是:
- active students – predicted 本身是主动的学生,并且被正确的预测;
- active students – missed 本身是主动的学生,但是被错误预测;
- drop students – predicted 本身是退学的学生,并且被正确的预测;
- drop students – missed 本身是退学的学生,但是被错误的预测;
3.4.2 时间轴视图
时间轴视图是对学生点击事件和作业提交数据的可视化(见图3 B区域)。其中,时间轴根据所属的学生大组分为了四个部分,而对于每个部分,每一条时间轴代表了聚类得到的子组信息。时间轴上每个节点代表了每一周的数据,而右侧的柱状图则编码了每个子组的人数分布。
时间轴上每一个节点的详细编码见图4(a),内圆环的外半径表示该子组同学在该周下观看视频的平均个数,内半径编码的则是观看视频个数的标准差,内圆环上利用不同颜色的扇形编码了该子组学生在该周所观看的视频时的点击行为所占比。外圆环则编码了该子组同学在该周的作业情况,圆环的弧长编码了作业的得分情况,越长越接近满分;外圆环上的黑色圆点编码了该子组同学该周平均得分百分比,两端的线段则编码了得分的标准差,之所以采用百分比的形式是因为每周作业的总分不同。
视频点击事件在扇形图上不好做直接比较,因此,作者在系统又设计了另外一个glyph(见图4(b)),用户可以在这两种glyph直接进行切换。

图4 时间轴glyph编码
3.4.3 流视图
流视图主要编码了子组学生在课程期间的发帖情况(见图3 C区域)。
3.4.4 仪表盘视图
仪表盘视图(见图3 D区域)由三部分组成,顶部的柱状图编码了预测结果的分布情况,中部是一个属性过滤器,方便用户进行过滤,重新计算聚类;最下面是和流视图相关的帖子的详细情况。
3.5 交互设计
系统中设计了一系列交互帮助用户更好的分析和探索,这些交互有:
过滤 用户可以通过仪表盘中部的过滤器调整用以聚类的属性,从而得到新的分析对象;
高亮 高亮能够更快更好地帮助用户定位到相关信息;
细节展示 当用户选择流视图中时间轴上某个时间节点时,该时间节点上的详细帖子将在仪表盘视图的下部展示;
重配 对于时间轴视图中的子组时间轴,用户可以对他们进行合并或者拆分;
4 案例分析
在案例研究中,作者对课程数据中前一个月的数据进行了训练,从而用来预测第五周的退学率,此外作者分别对JAVA和NCH课程的两个数据集都进行了可视化,并从得到了一些发现。
4.1 模型预测的准确性
通过可视化预测结果,可以发现,预测模型能够很好的预测学生的退学行为,预测的准确率能够达到90%,然而,对于主动学习的学生而言,模型似乎不太给力,预测准确率只能达到50%。
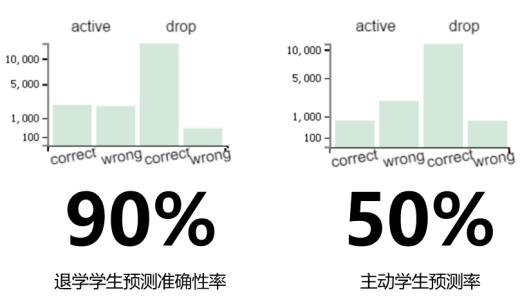
图5 预测模型准确率
4.2 学生退学行为很大程度上取决于课程本身
作者对JAVA和NCH的课程分别做了可视分析(见图6)后发现,JAVA课程中,第五周放弃课程的同学,在第六周之后又陆陆续续的回来了;然而NCH课程中,第五周放弃课程的同学,在第六周之后就再也没有回来了。通过分析,作者发现,Java课程在第五周之后又陆陆续续的在每周放出新视频激励学生学习;而NCH课程在第五周时,基本把所有的教学视频都发布了,剩下的几周用来复习和考试,所以流失了好多学生;所以说,学生在沉寂一周之后会不会再回到课堂,很大程度上取决于课程本身,或者说和课程发布的时间有很大关系。
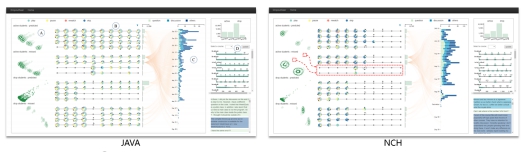
图6 JAVA和NCH课程可视化效果
为了验证这一猜想,用户选择NCH课程中,第二周没有视频点击行为的学生,发现他们也在第三周新的课程材料发布后返回了课堂(见图7)。这证明了,教学视频发布的频率是很重要的。
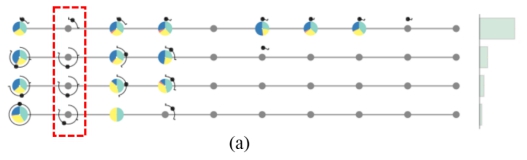
图7 NCH课程中,第二周没有任何视频点击行为的学生,在第三周的时候又返回了课堂
4.3 预测模型的特征重要性
用户在交互分析的时候,发现作业的表现对学生的退学行为有着非常大的影响,当用户通过属性过滤器过滤掉作业成绩低于某阈值的学生时发现,留下来的学生比较主动的学生;此外当用户通过属性过滤器过滤得到第四周作业成绩在2/3以上的学生时发现,这些学生均留到了课程结束。这两个发现能够说明,作业的表现很大程度上和退学有关,系统能够通过这种方式,在机器学习的研究人员在优化模型中的特征时给出一定的建议。
4.4 异常学生子组
用户过滤出前四周跳看次数在20次以上的学生,得到图8中(b)(c)两个视图,通过这两个视图我们可以发现,这些学生大部分都是属于主动学习的一类,并且他们的成绩一般比较优秀。
对于这个现象,讲师和教育人员给出了一定的原因,他们认为这类学生对课程有一定的基础,或者是已经不止一次的看过该视频,所以导致了这种情况发生。
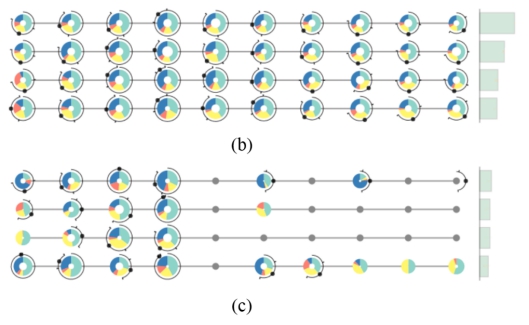
图8 每周跳看次数在20次以上的学生
5 总结
本文构建了一个针对MOOC退学行为研究的可视化分析系统,该系统不仅能够帮助机器学习研究人员更好的识别预测模型中的重要特征,还可以帮助讲师和教育人员理解学生退学行为背后的原因,并对课程作出一定的调整。系统易用,可视化射击简洁易懂,系统交互流畅,但是不足之处在于该系统不能够适配非“周更”的MOOCs课程,同时也不支持实时的退学预测。