DemographicVis: Analyzing Demographic Information based on User Generated Content
这篇文章提出一种基于用户生成信息的可交互式分析人口统计资料的系统——DemographicVis,它可以可视化那些从人口统计事实提取或者推断出的特征,以此来以一种透明的方式对人口统计信息进行探索。
因为之前基于年龄和性别的语义分析和根据常用词推断年龄性别等信息的系统都是只是以一种分类方式将人群简单分类,因此提出了使用年龄,性别,教育程度三种指标相结合的分类方式,并且设计了简明新奇的可视分析系统来展现人口统计资料和用户生成内容的关系。文章在最后还进行了user study 与SAS TextMiner 进行了定量的比较。

首先,其整个系统的构建流程就如上图所示。
首先进行的是数据的收集,对此,作者在Reddit.com上进行了问卷调查,收集到了409份用户的年龄,性别,学历等信息。之后其利用python 爬虫将Reddit中这些人的帖子全部爬取下来,共计169707个。时间上是从2011至今。
其次,就是提取描述每个人群的主题特征。为此,使用了Tag-LDA模型。在建模中,每个人群都为一个用户在reddit的每一次评论做了标记。提取主题时采用的是二元组词法,有先例证明该方法是比一元法更优秀的。
整个特征集包括三个部分:主题比例,语义特征和从元数据得到的额外特征。
用bag-of-word 模型在所有可用的reddit 帖子构建一个文档矩阵。随后用一个100维的主题集建立起主题模型,这样每个帖子都可以被一个100维的向量表示。最后把一个用户的所有帖子的向量加起来即得到一个reddit用户的主题比例。
语义特征是使用LIWC分析,从reddit的帖子中得到一个82维的向量。
额外特征是建立一个4296维的向量,维度是所有子版块的数目。再加上五维的特征向量,包括:一个用户的帖子总数,原始帖子占帖子总数的比例,点赞的总数,被赞的总数和其他用户写给这一用户的回复总数。
由此,对每个Reddit的用户我们都得到了一个4483维的向量。接着利用GBtree对人群进行了分类。作者利用了AUC方法评估不同特征在预测人群向量时的贡献。
接下来就进入了可视界面设计的阶段。
作者提出用户基本上会对三个问题感兴趣
- 不同的人群对什么感兴趣?不同人群可以从他们的帖子中反映出有着不同的兴趣吗?
- 那些人群有着相似的兴趣?
- 我们可以利用由社交媒体得到的帖子推断出的信息来把网络上的用户分为不同的人群吗?
针对这三个问题有三个主要界面被设计出来

如图所示,左侧是利用了平行坐标轴的视图将人群的分类直观表现出来,流的宽度也代表了人群人数的多少。中间的topic视图展现了随时间的变化主题数目的变化。最右的词云视图展现了一个主题所包含的关键词。当鼠标移到某一类人群或主题,对应的主题或人群也会高亮并展示出对应词云,因此可以直观展现人群与主题的关系,而点击一个主题也会显示出相关帖子的详细信息。

作者设计了一个简明的标记来表示一个人,形状代表性别,外圈染色多少代表年龄,中心的字母代表受教育程度。利用了t-SNE的降维法对高维的特征向量进行降维,将具有相似特征的聚到一起,对此我们从图像也可以看出,处于相同人群的人大都聚拢在一起。而有些聚拢在一起的不同人群正可以展现那些人群具有相似的特征。
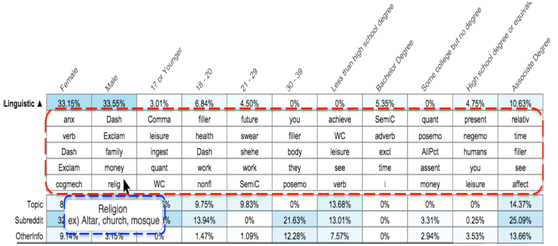
该表上半部展现了不同的特征在预测人口统计特征(即年龄,性别等)的贡献。下半部表示了对不同人口统计向量进行预测的失误率。
整个可视系统的全貌如下

作者通过两个case studies 展示了系统的便利,并且以user study 的形式与SAS TextMiner进行了比较,并取得了更好的成绩。
本文的作者从一个新奇的角度出发,以一种简洁的方式完成了一个比较完备的系统,并得到了较好的结果。作者最后也提到了未来的方向会是,收集更大的样本,在其他社交平台设计同样的问卷,以及提升特征分析的过程来达到更好的效果。