Sidebar
Table of Contents
第四课 时序数据分析
4.1 聚类
4.1.1 聚类的简介
1.定义
聚类是将数据点集分成由类似的点组成的多个类的过程,它是一种非监督的学习过程。

2.聚类与分类的区别
- 聚类
- 实例: \{ {\mathbf{x}}\}_{i=1}^N
- 过程:将本身没有类别的\bf{x}聚集到组t(\bf{x});
- 分类/回归
- 实例:<{\bf{x}}_i, t_i>, i=1, \ldots, N
- 过程:将数据\bf{x}映射到给定类别中的某一类t(\bf{x})中;
3.聚类的应用
聚类方法可以运用于图像分割领域, 下图就是两个运用Mean-shift方法作图像分割的例子。


4.1.2 几种聚类方法
1.层次(自底向上)聚类
- 思想: 顺序地将最近的两个点/类合并;
- 具体过程
- 找到两个最近的点(类),并将其合并;
- 重复上述操作,直至所有的点聚为一个类;
- 变量定义(可聚类的两个前提条件)
- 可以度量两个数据点间的距离:d(x_i, x_j);
- 可以度量两个类间的距离:
- 单点距离:d_{kl} = min_{x_i \in C_k, x_j \in C_l} d(x_i, d_j)
- 平均点距离:d_{kl} = \frac{1}{ |C_k| + |C_l| } \sum_{x_i \in C_k, x_j \in C_l} {d(x_i, d_j)}
- 质心距离:d_{kl} = d(c_l, c_k), c_k = \frac{1}{ |C_k| } \sum_{x_i \in C_k} {x_i}
- 层次聚类的树形图表示

- 其中,每一对数据点之间的高度为两个类之间的距离。
2.频谱聚类
- 三要素
- 最近点邻接图
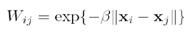 ;
; - 边的权值
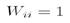 ;
;- 若两点间无边,则其权值为0;
- 变换成概率矩阵
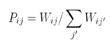 ;
;
- 随机漫步的性质

- 随着t的增大,t步后数据点的分布渐趋相似。若图为连通的,则最终的结果与初始点的选取无关。
- 本征值/向量及频谱分析

- 二进制频谱聚类
- 根据点的Z2值,将其分类,即:
- 当
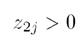 时,划分到类1,否则划到类0。
时,划分到类1,否则划到类0。
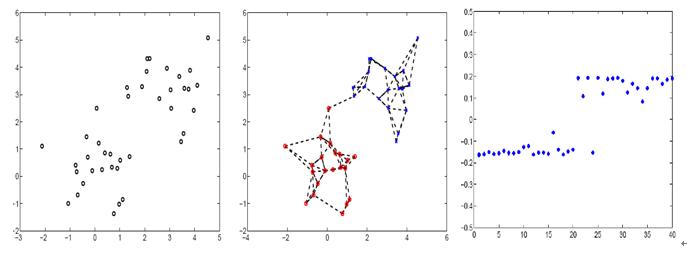
- 频谱聚类的实例







3.Flat聚类方法
1.K-means聚类
- 思想

- 具体过程



2.混合高斯聚类
K-means 是一种 hard-assign 的聚类方法,就是说,在 K-means 中一个数据点“确定地”属于某一个类别,而混合高斯聚类(Gaussian Mixture Model, GMM)中则采用了一种 soft-assign 的方法,它并不确定地将一个数据点划分到某个类别,而是给出了该点属于不同类别的概率,一方面,我们可以直接选取概率最大的那个分类,进行 hard-assign ,另一方面,由于有了概率信息,我们通常可以做更多的事情,例如拒绝处理“模糊不清”的边界点等等。
具体来说,GMM 假设数据是服从一个混合高斯分布,也就是许多个独立的高斯模型的加权,聚类的过程实际上就是对这个 model 进行 fitting 的过程,恢复出各个高斯模型的参数之后,每个数据点属于该类别的概率也就很自然地使用该高斯模型生成这个数据的概率来表示了。通常我们都使用最大似然的方式来对概率模型进行 fitting ,但是混合高斯模型由于对多个高斯分布进行加权,结果的概率式子很难解析地或者直接地求得最大似然的解,所以在计算的过程中采用了分布迭代的过程,具体是使用了一种叫做 Expectation Maximization (EM) 的方法,进行迭代求解。
GMM 有一些缺点,比如有时候其中一个 Gaussian component 可能会被 fit 到一个很小的范围内的点或者甚至单个数据点上,这种情况被称作 degeneration ,这个时候该模型的协方差矩阵会很小,而那里的概率值会变得非常大甚至趋向于无穷,这样一来我们可以得到极大的似然值,但是这样的情况通常并没有什么实际用处。解决办法通常是给模型参数加上一些先验约束,或者显式地检测和消除 degeneration 的情况。
另一个比较明显的缺点就是 GMM 模型中需要 fit 的参数非常多,特别是在维度较高的时候,协方差矩阵中需要 fit 的参数就极具增加了,这样的结果通常会导致很严重的 overfitting ,陷入唯独灾难中。一些可能的解决办法是限制协方差矩阵的结构,从而降低参数的个数。
4.2 隐马尔科夫模型
4.2.1 背景
马尔科夫性质
* 正式定义
一组随机变量序列X={X_n}n=0…N,其中X_k的取值为s_k且s_k∈N,
当且仅当P(X_m=s_m=|X_0=s_0,…, X_{m-1}=s_{m-1})
=P(X_0=s_0|X_{m-1}=s_{m-1}),则X满足马尔科夫性。
* 非正式定义
一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔科夫性。
马尔科夫链的历史
- 马尔科夫链理论发展于1900年
- 隐马尔科夫模型发展于六十年代晚期
- 在六七十年代广泛被用于语音识别
- 1989年被引入计算机科学
马尔科夫链的应用
- 生物信息学
- 信号处理
- 数据分析和模式识别
4.2.2 马尔科夫链
一条马尔科夫链由三要素确定:
状态空间——S={S_1, S_2, ,…, S_n}
初始分布——a_o
转移矩阵——A
其中A(n)_{ij}=a_{ij}=P(q_t=s_j|q_{t-1}=s_i)
图形表示——有向图

其中顶点代表状态,边代表状态间的跳转,权值是矩阵A的值.
概率公式(后面计算会用到得两个公式)
边际概率——联合概率的累加 P(x=a_i)=\sum p(x=a_i,y)
条件概率 P(x=a_i|y=b_j)=\frac{P(x=a_i|y=b_j)}{P(y=b_j)}\qquad if P(y=b_j)\ne0
马尔科夫链计算公式
设X={{x_i}^L}_t=0 是定义于马尔科夫链{S,a_o,A}下的一组随机变量序列,则
P(x)=P(x_L,,,,x_1,x_0)=P(x_L|x_{L-1})P(x_{L-1})|P(x_{L-2})…P(x_0)
\qquad=b_{x_0}\prod\limits_i^{L}a_{x_{i-1}}x_i
根据马尔科夫性化简,P(X_0)为初值
马尔科夫实例——描述
假设为丹麦秋天的高低气压随时间变化的序列建模。
设S={H,L},b=\pi=[\frac{3}{11},\frac{8}{11}],andA=\begin{equation}
\left[
\begin{array}{ccc}
0.2 & 0.8
\\0.3 & 0.7
\end{array}
\right]
\end{equation}
矩阵A的图示表示:

若想知道丹麦和加利福尼亚一周都出现高气压的可能性,已知序列x=HHHHHHH

根据马尔科夫链计算公式求得DK一周都出现高气压的概率非常小,而Cal的概率较大些
4.2.3 隐马尔科夫模型(HMM)
隐马尔科夫模型定义
HMM的状态时不确定或不可见的,只有通过观测序列的随机过程才能表现出来
观察到得事件与状态并不是一一对应,而是通过一组概率分布相联系
HMM是一个双重随机过程,两个组成部分:
马尔科夫链:描述状态的转移,用概率转移描述
一般随机过程:描述状态与观察序列间的关系,用观察值概率描述

观察数据间相互独立,但其背后的隐藏状态是一个马尔科夫链
用五元组M={S,V,A,B,\pi}描述隐马尔科夫模型,或简写为为\lambda==(\pi,A,B)
S={S_1,S_2,,,,,S_N} 状态集合
V={V_1,V_2,,,,,V_M}每个状态可能的观察值
A:与时间无关的状态转移概率矩阵,a_j=P(q_t=s_j|q_{t-1}=s_j)表示在t-1时刻、状态为S_i条件下,在t时刻状态为S_j的概率
B:给定状态下,观测概率分布,b_j(O_t)=P(O_t=V_j|q_t=s_j)表示在t时刻、状态S_j条件下,观察符号为V_j的概率
\pi:初始状态空间的概率分布,\pi={a_0}
隐马尔科夫模型序列生成
给定一个HMM,可以按如下步骤产生一个长度为n的观察序列:
1. 在状态q_1开始,根据概率a_{0t1}转移
2. 发射字母o_1根据e_{t1}(o1)
3. 进入状态q_2根据a_{t1t2}
4. ……直到发射出o_n

隐马尔科夫模型计算公式
给定一个状态序列Q=q_1q_2…q_T
对于Q的观察序列O是:
P(O|Q,\lambda)=\prod\limits_{t=1}^{T}p(O_t|q_t,\lambda)=b_{q1}(O_1).b_{q2}(O_2)…b_{qT}(O_T)
状态序列Q的概率为:
P(O|\lambda)=a_{0q1}a_{q1q2}a_{q2q3}…a_{qT-1qT}
Q和O同时发生的概率是上述两部分的点积
P(O|\lambda)=a_{0q1}a_{q1q2}a_{q2q3}…a_{qT-1qT}
P(O,Q|\lambda)=a_{0q1}b_{q1}(O_1)a_{q1q2}b_{q2}(O_2)a_{q2q3}…a_{qT-1qT}b_{qT}(O_T)
隐马尔科夫模型实例
高低气压模型:假设不能测量气压值,天气状况受大气压影响,可以建立HMM,隐藏状态用高低气压表示,观察值是天气状况,如下图:

隐马尔科夫模型计算公式
HMM求解公式为:
P(x,\pi)=(a_{OL}e_L(R)) (a_{LL}e_L(S)) (a_{LL}e_L(R)) (a_{LH}e_H(S)) (a_{HH}e_L(R))
\qquad=(\frac{8}{11}\frac{8}{10})(\frac{7}{10}\frac{8}{10})(\frac{7}{10}\frac{2}{10})(\frac{7}{10}\frac{8}{10})(\frac{3}{10}\frac{8}{10})(\frac{2}{10}\frac{8}{10})(\frac{8}{10}\frac{8}{10})
\qquad=0.0006278
隐马尔科夫模型的三个基本问题
HMM可基本总结为对三类基本问题的求解:
1. 赋值问题
给定观察序列O以及模型M={S,V,A,B,\pi},如何计算P(O|M)?
2. 解码问题
给定观察序列O以及模型M={S,V,A,B,\pi},如何选择一个对应的状态序Q,使得Q能够最为合理的解释观察序O,即最大化P(O,Q|\lambda)?
3. 学习问题
给定模型M={S,V,A,B,\pi},但没有指定A,B,如何调整模型参数(\pi,A,B)使得观测序列O的概率最大?
基本算法——针对以上三个问题,提出相应的算法
隐马尔科夫模型的赋值问题
解决HMM的赋值问题可采用:
1)基础方法——穷举法
给定一个固定的状态序列S=(q_1,q_2,q_3…)通过累加所有可能的状态序列q
P(O|S,\lambda)=\prod\limits_{t=1}^{T}P(O_t|q_t,\lambda)=b_{q_1}(O_1) b_{q_2}(O_2)…b_{q_t}(O_T)
b_{q_t}(O_T)表示在q_t状态下观测到O_t的概率
则
P(O|\lambda)=\sum\limits_{所有s}P(O|S,\lambda) P(O|\lambda)
计算复杂性为O(N^7)
2) 前向算法:动态规划的思想
定义前向变量: \alpha _t(i)=P(O_1O_2…O_i,q_i=S_i|\lambda)
初始化 \alpha _l(i)=a_{oi}b_{oi}(O_i) i=1…N
迭代 \overline{\alpha_{t+1}(i)}=[\sum\limits_{i=1}^{N}\alpha_t(i)a_{ij}]b_j(O_{t+1})
终止 P(O|\lambda)=\sum\limits_{i=1}^{N}\alpha_T(i)
3) 后向算法:与前向算法类似
定义后向变量: \beta_t(i)=P(O_{t+1}O_{t+2}…O_T|q_t=S_i,\lambda)
初始化 \beta_T(i)=1, i=1,…,N
迭代 \beta_T(i)= \sum\limits_{j=1}^{N}a_{ij}b_j(O_{t+1})\beta_{t+1}(j)
终止 P(O|\lambda)=\sum\limits_{j=1}^{N}a_{0j}b_1(O_1)\beta_1(j)
隐马尔科夫模型的赋值问题
目的:P(Q|O,\lambda)=\frac{ P(O|Q,\lambda)}{ P(O|\lambda)}
最大化 等价于最大化 P(Q|O,\lambda)=a_{i_1} b_{i_1o_1} a_{i_1i_2} b_{i_2o_2} a_{i_2i_3} b_{i_3o_3}…. a_{i_{T-1}i_T} b_{i_To_T}
这是寻找最佳路径问题
Viterbi 算法(N是状态数目,T是序列长度)
初始化:
终止:
算法示意图如下所示:

据此可知, Viterbi算法的时间复杂度为O(K^2N), 空间复杂度 O(KN)
隐马尔科夫模型的学习问题
估计HMM的参数分两种情况:
1) 观察序列O和状态序列Q已知,学习模型 \lambda=(A,B,\pi)
2) 只有观察序列O已知,需要学习状态序列和模型 \lambda=(A,B,\pi)
针对情况一:
给定序列Q和O,则参数的似然值由下式给出
L(A,B,\pi)=a_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2} a_{i_2i_3} b_{i_3o_3}…. a_{i_{T-1}i_T} b_{i_To_T}
log似然值为
l(A,B,\pi)=ln L(A,B,\pi)
\qquad=ln(a_{i_1})+ln (b_{i_1o_1})+ln(a_{i_1i_2})+ln(a_{i_2i_3})
+ln(b_{i_3o_3})+…+ln(a_{i_{T-1}i_T})+ln(b_{i_To_T})
\qquad=\sum\limits_{i=1}^{M}f_{i0}ln(a_i)+\sum\limits_{i=1}^{M}\sum\limits_{j=1}^{M}f_{ij}ln(a_{ij})+\sum\limits_{i=1}^{M}\sum\limits_{j=1}^{M}ln(b_{io})
其中f_{io}等于状态i在首次状态发生的次数
f_{ij}=等于状态i转换到状态j的次数
\beta_{ij}=f(y|\theta_i)
\sum\limits_{o(i)}=在状态q_t=S_i条件下,所有观察值为o_t的总和
这时参数可由最大似然计算得出
\widehat{a_i}=\frac{f_{i0}}{1} \widehat{a_{ij}}=\frac{f_{ij}}{\sum\limits_{j=1}^{M}f_{ij}}
\widehat{b_i}=MLE,由在状态q_t=S_i条件下,所有观察值为o_t计算
针对情况二:只有观察序列O已知
L(A,B,\pi)=\sum\limits_{i_1,i_2…i_T}a_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2} a_{i_2i_3} b_{i_3o_3}…. a_{i_{T-1}i_T} b_{i_To_T}
难以直接从似然函数找到最大似然估计,于是可以采用分段K均值算法和Baum-Welch(E-M)算法来解决。
4.2.4 Buam-Welch算法
- 最初设计E-M算法是用来处理“缺失的观察”问题的。
- “缺失的观察”是状态{q1,q2,…,qT}
- 设已有模型,通过找出它们在该模型下的期望值来估计出相应的状态。(E-M算法中E的那一部分)
- 通过最大似然估计,使用这些取值计算出模型。(E-M算法中M的那一部分)
- 这个过程不断重复,直至模型收敛.
算法具体分为两步:
1. 初始化
为模型参数估计最佳值(或者任意选取)
2. 迭代
前行
后向
计算Akl,Ek(b)
计算新的模型参数akl,ek(b)
计算新的日志似然P(X|\lambda)直到P(X|\lambda)不再变化
设f(O,Q|\lambda)=L(O,Q,\lambda)表示Q,O的联合分布,从初始估计\lambda(\lambda)(1),考虑如下函数:

根据\lambda,查找\lambda=\lambda(m+1)来最大化Q(\lambda,\lambda(m)),则形成估计值序列{\lambda(m))}。
该估计值序列收敛于似然的极大值
L(Q,\lambda)=f(Q|\lambda)

4.2.5 语音识别
1. 基于Java的语音识别API在线文档
http://java.sun.com/products/java-media/speech/
2. free TTS的在线文档
http://freetts.sourceforge.net/docs/
3. Sphinx-II的在线文档
http://www.speech.cs.cmu.edu/sphinx/
CMU Sphinx的简短历史回顾
1. Sphinx-I (1987)
世界上第一个与用户无关,高性能的ASR
由李开复博士(原Google副总裁)使用C语言编写
2. Sphinx-II (1992)
由黄学东博士使用C语言编写(现微软Speech.net团队领导人)
5-state HMM / N-gram LM.
3. Sphinx-III (1996)
由Eric Thayer和Mosur Ravishankar合作开发。
虽然比Sphinx-II慢,但设计更灵活
4. Sphinx-4 (起初是 Sphinx 3j)
基于Sphinx-III改造
完全是基于Java平台的
CMU Sphinx的组成部分

它的知识库包括:
驱动解码器的数据
三种数据集:
声音模型 语言模型 词汇表

语音识别架构
1) 观察:
2) 单词序列:
3) 表达可能的实现:

4) 使用贝叶斯公式拆分:


5) 对每个句子,我们仍然检测相同的观察O,它必须有相同的概率P(O):



声音模型
1) /model/hmm/6k
2) 统计模型数据库
3) 每个统计模型表示一个现象
4) 通过分析大量语言数据来训练声音模型
声音模型中的HMM
1) HMM表示声音模型中的一组语音
2) 典型的HMM用3到5个状态来表示一个现象
3) HMM的状态通过一组高斯混合密度函数来表达
4) Sphinx2(缺省声音集)
混合高斯函数
1) 表示HMM中的状态
2) 称每组高斯函数集为“senones”
3) HMM可以共享“senones”


 其中
其中

只要有足够的混合成分,高斯混合函数可以逼近任何分布

语言模型
- 在一个具体的上下文环境中,描述那些很可能被说出的内容
- 以变换概念来定义词变换
- 有助于约束(限制)搜索空间

N分图 语言模型
- 词N出现的频率依赖于词N-1,N-2,…
- 通常使用2分图和3分图
- 用于大词汇量的应用(如检测)
- 选取大型文件库(百万计的词汇)作为训练样本

马尔科夫随机场
http://www.nlpr.ia.ac.cn/users/szli/MRF_Book/MRF_Book.html

信任网络(传播)
- 作者: Y. Weiss 和 W. T. Freeman
- 来自文献: Correctness of Belief Propagation in Gaussian Graphical Models of Arbitrary Topology. in: Advances in Neural Information Processing Systems 12, edited by S. A. Solla, T. K. Leen, and K-R Muller, 2000.



4.3 卡尔曼滤波器
4.3.1 简介
鲁道夫·卡尔曼(Rudolf Emil Kalman),匈牙利裔美国数学家,1930年出生于匈牙利首都布达佩斯。1953年于麻省理工学院获得电机工程学士,翌年硕士学位。1957年于哥伦比亚大学获得博士学位。1964年至1971年任职斯坦福大学。1971年至1992年任佛罗里达大学数学系统理论中心(Center for Mathematical System Theory)主任。1972起任瑞士苏黎世联邦理工学院数学系统理论中心主任直至退休。先居住于苏黎世和佛罗里达。2009年获美国国家科学奖章。
1960年,卡尔曼发表了他著名的用递归方法解决离散数据线性滤波问题的论文。从那以后,得益于数字计算技术的进步,卡尔曼滤波器已成为推广研究和应用的主题,尤其是在自主或协助导航领域。
卡尔曼滤波器由一系列递归数学公式描述。它们提供了一种高效可计算的方法来估计过程的状态,并使估计均方误差最小。卡尔曼滤波器应用广泛且功能强大:它可以估计信号的过去和当前状态,甚至能估计将来的状态,即使并不知道模型的确切性质。
4.3.2 被估计的过程信号
卡尔曼滤波器用于估计离散时间过程的状态变量x∈Rn。这个离散时间过程由以下离散随机差分方程描述:
xk=Axk-1+Buk-1+wk-1,
定义观测变量z∈Rm,得到量测方程:
zk=Hxk+vk。
随机信号wk和vk分别表示过程激励噪声和观测噪声。假设它们是相互独立正态分布的白色噪声:
p(w)~N(0,Q),
p(v)~N(0,R)。
4.3.3 滤波器的计算原型
定义 ∈Rn为在已知第k步以前状态情况下第k步的先验状态估计。定义
∈Rn为在已知第k步以前状态情况下第k步的先验状态估计。定义 为已经测量变量zk时第k步的后验状态估计。由此定义先验估计误差和后验估计误差:
为已经测量变量zk时第k步的后验状态估计。由此定义先验估计误差和后验估计误差:
 :=xk-,
:=xk-,
ek:=xk-
先验估计误差的协方差为:

后验估计误差的协方差为:

下式构造了卡尔曼滤波器的表达式:

先验估计和加权的测量变量zk及其预测H之差的线性组合构成了后验状态估计。
nXm阶矩阵K叫做残余的增益或混合因数,作用是使后验估计误差协方差最小。K的一种表示形式为:

由上式可知,观测噪声协方差R越小,残余的增益越大K越大。特别地,R趋向于零时,有:

另一方面,先验估计误差协方差 越小,残余的增益K越小。特别的,趋向于零时,有:
越小,残余的增益K越小。特别的,趋向于零时,有:

4.3.4 滤波器的概率原型
贝叶斯规则:的更新取决于在已知先前的测量变量zk的情况下xk的先验估计的概率分布。卡尔曼滤波器表达式中包含了状态分布的前二阶矩。


在已知zk的情况下,xk的分布可写为:

4.3.5 离散卡尔曼滤波器算法
卡尔曼滤波器用反馈控制的方法估计过程状态:滤波器估计过程某一时刻的状态,然后以(含噪声的)测量变量的方式获得反馈。因此卡尔曼滤波器可分为两个部分:时间更新方程和测量更新方程。时间更新方程负责及时向前推算当前状态变量和误差协方差估计的值,以便为下一个时间状态构造先验估计。测量更新方程负责反馈——也就是说,它将先验估计和新的测量变量结合以构造改进的后验估计。时间更新方程也可视为预估方程,测量更新方程可视为校正方程。
时间更新方程:

测量更新方程:

卡尔曼滤波器工作原理图:

4.3.6 滤波器系数及调整
滤波器实际实现时,测量噪声协方差R一般可以观测得到,是滤波器的已知条件。观测测量噪声协方差R一般是可实现的(可能的),毕竟我们要观测整个系统过程。因此通常我们离线获取一些系统观测值以计算测量噪声协方差。 通常更难确定过程激励噪声协方差的Q值,因为我们无法直接观测到过程信号xk。有时可以通过Q的选择给过程信号“注入”足够的不确定性来建立一个简单的(差的)过程模型而产生可以接受的结果。当然在这种情况下人们希望信号观测值是可信的。 在这两种情况下,不管我们是否有一个合理的标准来选择系数,我们通常(统计学上的)都可以通过调整滤波器系数来获得更好的性能。调整通常离线进行,并经常与另一个(确定无误的)在线滤波器对比,这个过程称为系统识别。
4.3.7 扩展卡尔曼滤波器
为了估计一个具有非线性差分和量测关系的过程,A变成a(x),H变成h(x),有下式:
xk=a(xk-1)xk-1+Buk-1+wk-1
zk=h(xk-1)xxk-1+vxk-1
