Multi-Granularity Context Network for Efficient Video Semantic Segmentation
IEEE Transactions on Image Processing, 2023, 32: 3163-3175.
Zhiyuan Liang, Xiangdong Dai, Yiqian Wu, Xiaogang Jin, and Jianbing Shen
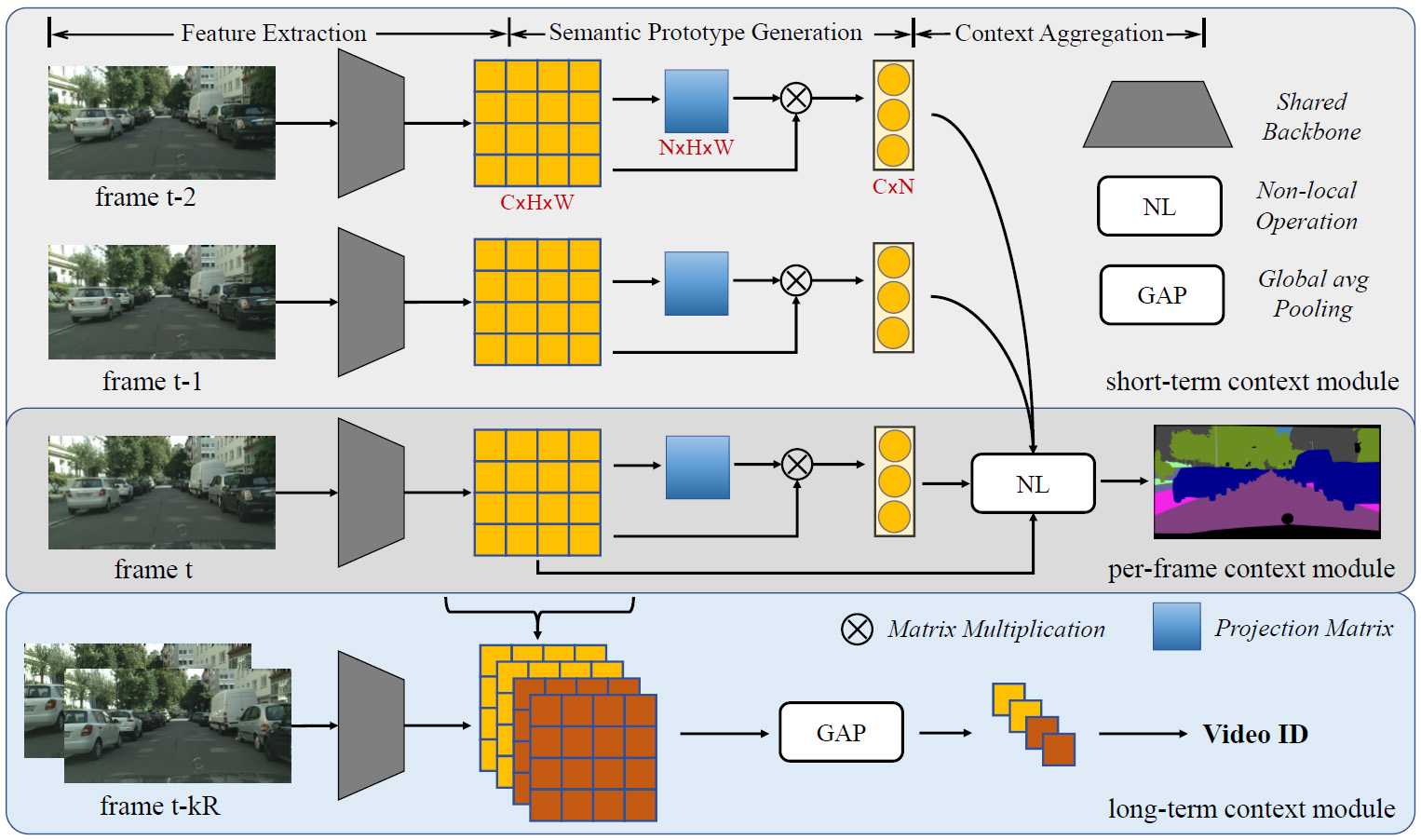
The network architecture of the MGCNet. It adopts a shared backbone to extract image features at each frame and then leverages the per-frame, short-term, and long-term context modules to capture context information at different granularities during training. The pixel-to-prototype non-local operation is proposed for both per-frame and short-term context modules. The long-term context module is removed to maintain the high speed at the inference time. R is the frame interval for the distant frame selection.
Abstract
Current video semantic
segmentation tasks involve two main challenges: how to take full advantage
of multiframe context information, and how to improve computational
efficiency in video processing. To tackle the two challenges simultaneously,
we present a novel Multi-Granularity Context Network (MGCNet) by aggregating
context information at multiple granularities in a more effective and
efficient way. Our method first converts image features into semantic
prototypes, and then conducts a non-local operation to aggregate the
perframe and short-term contexts jointly. An additional long-term context
module is introduced to capture the video-level semantic information during
training. By aggregating both local and global semantic information, a
strong feature representation is obtained. The proposed pixel-to-prototype
non-local operation requires less computational cost than traditional
non-local ones, and is video-friendly since it reuses the semantic
prototypes of previous frames. Moreover, we propose an uncertainty-aware and
structural knowledge distillation strategy to boost the performance of our
method. Experiments on Cityscapes and CamVid datasets with multiple
backbones demonstrate that the proposed MGCNet outperforms other
state-of-the-art methods with high speed and low latency.