
浙江大学计算机辅助设计与图形系统全国重点实验室金小刚教授课题组在SIGGRAPH 2025会议上,发表名为“Text-based Animatable 3D Avatars with Morphable Model Alignment”的研究论文,提出了创新框架AnimPortrait3D,可实现基于文本的真实可动3D高斯泼溅虚拟人生成,同时确保了与可变形模型的对齐。该研究引入了两项关键技术:首先,利用预训练的文本到3D模型的先验信息初始化虚拟人,确保其外观、几何及与可变形模型的绑定关系具有鲁棒性;其次,采用以可变形模型渲染的语义分割图和法线图为条件的ControlNet优化初始3D虚拟人的动态表情,实现精准对齐。本方法在合成质量、对齐精度和动画保真度方面均超越现有技术,推动了基于文本的可动画3D头部虚拟人生成领域的进展。
研究背景
基于文本生成高质量、可动画化的3D虚拟人在游戏、电影和具身虚拟助手等内容创作领域具有巨大潜力。现有的一种流行的文本到3D生成方法通常将参数化头部模型与2D扩散模型通过分数蒸馏采样相结合以产生3D一致结果,但存在细节真实性不足、外观与底层驱动参数模型错位导致动画效果不自然等问题。
这些问题主要源于两个关键因素:i) 扩散模型中,单个文本提示对应广泛的图像分布。单个文本提示在扩散模型中映射到多样化的图像空间,导致对外观和几何的约束不足,从而产生模糊结果及”双面”问题(Janus问题)。之前的方法通过采用外观-几何联合先验缓解该问题,但其生成的几何结构存在噪声,且仅限于静态重建而无法支持动画人脸。ii) 扩散模型预测与参数化模型对齐不足。扩散模型的预测通常与底层参数化模型对齐不佳,导致动画过程中出现伪影。之前的方法尝试通过基于面部标志点的ControlNet进行引导,但仅依赖标志点提供的3D信息难以实现鲁棒对齐。核心挑战在于如何将参数化模型的几何与语义信息共同融入优化过程,形成强约束的引导机制。
研究创新与突破
该研究提出创新框架AnimPortrait3D,通过文本描述生成兼具真实外观、精确几何且与参数化网格严格对齐的可动画3D虚拟人。AnimPortrait3D包含两阶段:初始化阶段:从一个已有的文本-静态3D人脸模型获取高质量外观与几何先验,通过SMPL-X模型拟合实现动画化基础。针对SMPL-X未建模的头发与衣物,从初始虚拟人提取噪声网格后利用法向图优化,并借助预训的语义分割网络进行组件分离,得到头发与衣物网格。随后将SMPL-X、头发及衣物网格纹理化为3D高斯表征,优化外观特征。动态优化阶段:为解决静态优化导致的动画伪影,该研究引入基于SMPL-X法向图与分割图训练的ControlNet,提供几何-语义协同引导。针对眼睑、口腔等具有复杂几何结构与频繁遮挡特性的区域,该研究实施单独的优化策略:在眼部区域,通过扩散模型与ControlNet生成高精度眼部参考图像,以此指导3D虚拟人眼部细节的优化过程;对于口腔区域,则引入间隔分数匹配(ISM)损失,有效增强该区域在动态表情下的纹理细节表现力。最终,该研究通过间隔分数匹配(ISM)优化整体虚拟人,并利用扩散模型细化图像进一步消除微伪影,提升整体质量。综上,该研究作出以下贡献:
一种创新型3D虚拟人生成框架,能够基于文本描述生成具有优异合成质量与动画保真度的可动画3D虚拟人。该框架通过多阶段优化机制,有效解决了现有方法在细节真实性与运动一致性方面的局限性。
一种新颖的可动画3D虚拟人初始化策略。该策略通过几何与外观的联合初始化,不仅确保了初始虚拟人的视觉质量,还建立了与参数化模型之间稳定的绑定关系,为后续动画控制奠定了坚实基础。
一种基于几何与语义感知的动态姿势优化方法。该方法创新性地利用ControlNet提供的多模态引导信号,在表情与姿态变化过程中保持虚拟人与驱动参数化模型的精确对齐,显著提升了动画过程中的视觉连贯性。

本方法系统框架示意图
研究成果与贡献
下面介绍AnimPortrait3D生成的结果以及与其他方法的对比。该研究采用相同的文本提示作为输入,将AnimPortrait3D与当前最先进的可动画3D虚拟人生成方法进行比较,包括HeadStudio、TADA和HumanGaussian。此外,还与3D虚拟人编辑方法PortraitGen,和基于3DGS的头部重建模型(GPAvatar和GAGAvatar)作比较。
上图中展示了定性比较结果。AnimPortrait3D在发丝、眼部及口腔等挑战性区域表现优异:通过ControlNet的集成,显著提升了复杂区域的动态表情对齐精度与可控性;独特的初始化策略则保障了多视角(包括高难度背视图)下的细节真实感,实现了外观细节的精准保持。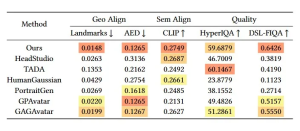
上表中展示了定量比较结果。该研究采用统一的20组文本提示(10组男性描述和10组女性描述)为每种方法生成对应的虚拟人。为全面评估生成质量,每个虚拟人渲染100张随机视角图像,其相机参数与表情参数均从NeRSemble数据集中随机采样。AnimPortrait3D在指标上优于现有方案或与现有方案相当。
本研究由浙江大学计算机辅助设计与图形系统全国重点实验室金小刚教授担任通讯作者。第一作者博士研究生吴奕谦在苏黎世联邦理工学院计算机视觉与学习小组(Computer Vision and Learning Group)访学期间完成该研究工作,得到Siyu Tang教授与金小刚教授的联合指导。论文第二作者Malte Prinzler获得马克斯普朗克 ETH 学习系统中心 (CLS) 资助。本研究获得浙江省重点研发计划项目,国家自然科学基金项目和瑞士国家科学基金会(Swiss National Science Foundation)项目支持。
