Table of Contents
<note important> 请各位同学注意:
- 要学会分节叙述,从而在dokuwiki中进行较为方便地编辑。具体方法请参考2010学年的编辑内容。
- 如果摘抄的是相关资料,请注意填写后面的参考文献,避免存在版权问题。
- 各位同学的帐号是大家的学号,初始密码是“123456”,请登录后修改相关个人信息。
by 张老师 2011-09-23 </note>
第6课 多媒体数据库系统
6.1多媒体内容结构
6.1.1元数据模型结构
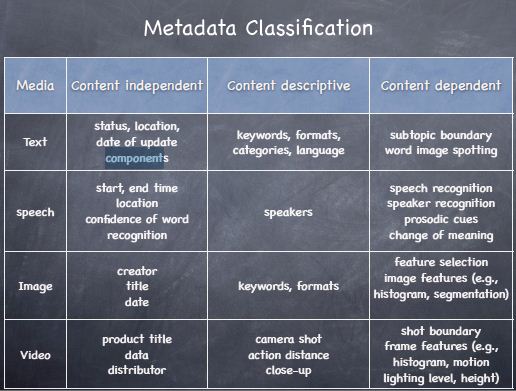
元数据(Metadata)被分为三层:
- 依赖性内容
- 描述性内容
- 独立性内容
6.1.2元数据模型
元数据的定义:data about data
- 元数据形成了数据库的必要组成部分,对存储的对象进行描述,同时是组织和管理数据对象的关键。
- 包含描述内容的关键信息。比如:
标题,作者,语言,出版商,etc. 事件,情形,对象,时间,地点etc.
- 元数据的应用目的(Purpose)
- 管理数据(Administrative)
- 描述数据(Descriptive)
- 保存数据(Preservation)
- 数据所包含的技术要点(Technical)
- 使用权限(Usage)
- 元数据模型与开源元数据标准一致性(Conformity)
- 更快的设计和应用
- 竞争环境下的工具和系统将有更好的互操作性
- 可以划分领域提供不同功能
- 元数据在检索流程中的角色

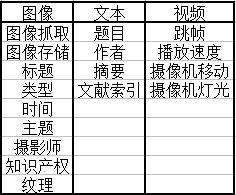
6.1.3元数据的分类
- 元数据的分类标准可以是:
- 对包含的媒体的详述
- 对过程的详述
- 对数据的详述
- 元数据的举例:
- 元数据可以被分成:
- 依赖性内容
- 描述性内容
- 独立性内容
举例:
6.1.4元数据的标准
1、Domain-dependant Metadata Standards(非独立域的数据元标准)
- Digital geospatial metadata
by US Geographic Data Committee
- Environmental data (UDK)
by the European Environmental Catalog
- Product data exchange (PDES)
an ANSI standard for the exchange of product model data
- Rich Site Summary (RSS)
a lightweight XML vocabulary for describing websites, ideal for news syndication
- Medical information (HL7)
provides specification for hospital records and medical information management accredited by ANSI
2、Domain-independent Metadata Standards(独立域的数据元标准)
- ISO/IEC 11179
此标准用于提供:
a 概念体系 b 逻辑描述 c 数据与元数据直接的交换
此标准把数据元素分为3个部分:
a 对象 b 属性 c 表现
更多信息参见:http://metadata-standards.org/11179/
- The Dublin Core Metadata set
broaden to other media with a link to the ISO/IEC 11179 standard
a 每个都柏林核元素由10个来自ISO/IEC 11179标准的属性定义, b 其中6个属性都柏林核元素中广泛存在(下图所示属性3,4,5,7,8,9)
- 15 metadata elements (the Dublin Core) has been proposed

- ItemResource Description Framework (RDF)(资源描述框架)
a 被W3C提高而当作数据处理元数据的基础 b 允许多样元数据方案被人类阅读并且被机器从语法上分析 c 具体目标包括:
资源发现-提供更好的搜索引擎容量 目录-描述智能软件代理中目录和有效的关系 内容等级-描述代表独立的合乎逻辑的”文件”的页的合集 知识产权-描述网页的知识产权 隐私优先与政策-用于用户与站点 数字签名-建立一个用于商业贸易、合作和其他应用的”信任网页”资源描述的构架
- ItemRDF构架的正式模型
a 包含以下集合:资源、文字、属性(资源的子集)、 声明(其中每个元素是形式如同<pred, sub, obj>的三元组,pred是属性,sub是资源,obj是资源或者文字) b 书写RDF计划的语言是XML
6.1.5 XML
Overview of XML
Introduction
XML(Extensible Markup Language)即可扩展标记语言,它与HTML一样,都是SGML(Standard Generalized Markup Language,标准通用标记语言)。Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。扩展标记语言XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立,虽然XML占用的空间比二进制数据要占用更多的空间,但XML极其简单易于掌握和使用。
Example
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
XML Conceptual View
XML是可扩展标记语言 An XML document is a (Unicode) text with markup tags and other meta-information. XML是有标签和其他信息的纯文本:
■所有 XML 元素都须有关闭标签。
■XML 标签对大小写敏感。
■XML 必须正确地嵌套。
■XML 的属性值须加引号。
■实体引用:
在 XML 中,一些字符拥有特殊的意义。如果你把字符 ”<” 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。 这样会产生 XML 错误: <message>if salary < 1000 then</message>
为了避免这个错误,请用一个实体引用来代替 ”<” 字符: <message>if salary < 1000 then</message>
Property
XML与Access,Oracle和SQL Server等数据库不同,数据库提供了更强有力的数据存储和分析能力,例如:数据索引、排序、查找、相关一致性等,XML仅仅是展示数据。事实上XML与其他数据表现形式最大的不同是:它极其简单。这是一个看上去有点琐细的优点,但正是这点使XML与众不同。
XML与HTML的设计区别是:XML是用来存储数据的,重在数据本身。而HTML是用来定义数据的,重在数据的显示模式。 XML的简单使其易于在任何应用程序中读写数据,这使XML很快成为数据交换的唯一公共语言,虽然不同的应用软件也支持其它的数据交换格式,但不久之后他们都将支持XML,那就意味着程序可以更容易的与Windows、Mac OS, Linux以及其他平台下产生的信息结合,然后可以很容易加载XML数据到程序中并分析他,并以XML格式输出结果。 为了使得SGML显得用户友好,XML重新定义了SGML的一些内部值和参数,去掉了大量的很少用到的功能,这些繁杂的功能使得SGML在设计网站时显得复杂化。XML保留了SGML的结构化功能,这样就使得网站设计者可以定义自己的文档类型,XML同时也推出一种新型文档类型,使得开发者也可以不必定义文档类型。 因为XML是W3C制定的,XML的标准化工作由W3C的XML工作组负责,该小组成员由来自各个地方和行业的专家组成,他们通过email交流对XML标准的意见,并提出自己的看法 (www.w3.org/TR/WD-xml)。因为XML 是个公共格式, (它不专属于任何一家公司),你不必担心XML技术会成为少数公司的盈利工具,XML不是一个依附于特定浏览器的语言
XML英文解释 The Extensible Markup Language (XML) is a general-purpose specification for creating custom markup languages.It is classified as an extensible language, because it allows the user to define the mark-up elements. XML's purpose is to aid information systems in sharing structured data, especially via the Internet, to encode documents, and to serialize data; in the last context, it compares with text-based serialization languages such as JSON and YAML.XML began as a simplified subset of the Standard Generalized Markup Language (SGML), meant to be readable by people via semantic constraints; application languages can be implemented in XML. These include XHTML,RSS, MathML, GraphML, Scalable Vector Graphics, MusicXML, and others. Moreover, XML is sometimes used as the specification language for such application languages.XML is recommended by the World Wide Web Consortium (W3C). It is a fee-free open standard. The recommendation specifies lexical grammar and parsing requirements.
简明语法

SGML常用来定义针对HTML的文档类型定义(DTD),同时它也常用于编写XML的DTD。SGML的问题就在于,它允许出现一些奇怪的语法,这让创建HTML的解析器成为一个大难题:
1 某些起始标签不允许出现结束标签,例如HTML中<img>标签。包含了结束标签就会出现错误。
2 某些起始标签可以选择性出现结束标签或者隐含了结束标签
3 某些起始标签要求必须出现结束标签,例如HTML中<script>标签。
4 标签可以以任何顺序嵌套。即使结束标签不按照起始标签的逆序出现也是允许的,例如,This is a sample string是正确的。
5 某些特性要求必须包含值,例如<img src=“picture.jpg”>中的src特性。
6 某些特性不要求一定有值,例如中的nowrap特性。
7 定义特性的两边有没有加上双引号都是可以的,所以<img src=“picture.jpg”>和<img src=picture.jpg>都是允许的。
这些问题使建立一个SGML语言的解析器变成了一项艰巨的任务。判断何时应用以上规则的困难导致了SGML语言的定义一直停滞不前。以这些问题作为出发点,XML逐渐步入我们的视野。
XML去掉了之前令许多开发人员头疼的SGML的随意语法。在XML中,采用了如下的语法:
1 任何的起始标签都必须有一个结束标签。
2 可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号之前紧跟一个斜线(/),例如<tag />。XML解析器会将其翻译成<tag></tag>。
3 标签必须按合适的顺序进行嵌套,所以结束标签必须按镜像顺序匹配起始标签,例如this is a samplestring和</script><script>while(1){alert(“this is a samplestring”)}</script>这好比是将起始和结束标签看作是数学中的左右括号:在没有关闭所有的内部括号之前,是不能关闭外面的括号的。
4 所有的特性都必须有值。
5 所有的特性都必须在值的周围加上双引号。
这些规则使得开发一个XML解析器要简便得多,而且也除去了解析SGML中花在判断何时何地应用那些奇怪语法规则上的工作。仅仅在XML出现后的前六年就衍生出多种不同的语言,包括MathML、SVG、RDF、RSS、SOAP、XSLT、XSL-FO,而同时也将HTML改进为XHTML。
如果需要关于SGML和XML具体技术上的对比,请查看W3C的注解,位于:http:///TR/NOTE-sgml-xml.html
如今,XML已经是世界上发展最快的技术之一。它的主要目的是使用文本以结构化的方式来表示数据。在某些方面,XML文件也类似于数据库,提供数据的结构化视图。这里是一个XML文件的例子:
eg
<?xml version=“1.0” encoding=“ISO-8859-1”?>
<bookstore>
<book catalog=“Programming”>
<title lang=“en”>C++ Programming Language</title>
<author>Bjarne Stroustrup</author>
<year>1998</year>
<price>98.0</price>
</book>
<book catalog=“Networking”>
<title lang=“en”>TCP/IP Illustrated</title>
<author>Richard Stevens</author>
<year>1996</year>
<price>56.0</price>
</book>
</bookstore>
XML和HTML的差异
XML和HTML的不同可以归纳为3点:
① XML扩展性比HTML强 XML(Extensible Markup Languages)是扩展标记语言的英语缩写,他可以创建个性化的标记语言,可以称之为元语言。XML的标记语言可以自定义,这样可以提供更多的数据操作,而不像HTML一样,只能局限于按一定的格式在终端显示出来。HTML的功能只有浏览器放入显示和打印,仅仅适合静态网页的要求。
② XML的语法比HTML严格 由于XML的扩展性强,它需要稳定的基础规则来支持扩展。它的严格规则为: 1、起始和结束的标签相匹配 2、嵌套标签不能相互嵌套 3、区分大小写 相对应XML的严格规则,HTML语言并没有规定标签的绝对位置,也不区分大小写,而这些全部由浏览器来完成识别和更正。
③ XML与HTML互补 XML可以获得应用之间的相应信息,提供终端的多项处理要求,也能被其他的解析器和工具所使用,在现阶段,XML可以转化成相应的HTML,来适应当前浏览器的需求。 XML 工具
XML如果有一个好的编辑器就能够减少很多麻烦
1 、XML Notepad 一种软件 软件大小: 1872 KB 软件语言: 英文 软件类别: 国外软件 / 共享版 / 字体工具 应用平台: Win9x/NT/2000/XP/2003 微软发布的XML Notepad,这是一个简单+好用的XML阅读和编辑工具,支持多种语法显示和数型结构排列并提供了大量编写XML所需的工具.
2、XML Spy
3、Xeena
4、Xmetsal
6.1.6 MPEG-7
■多媒体内容描述接口
1.关于内容的信息
静止图片,图形,三维模型,音频,语音,视频以及它们的结合
2.目标
支持使用标准描述的多媒体内容的有效搜索 最好用文本信息的描述
■域名独立元数据标准
1.描述符(DS):描述的功能,属性或属性组的MM内容
2.描述方案(DSs):DS指定的结构和语义的组件 (可能是其他Dss,DS,或数据类型)
3.数据类型
4.分类计划(CS):列出了明确的条款及意义
5.系统工具
6.可扩展性:例如,新的DS’s和D’s,CS的注册权
6.2多媒体数据库系统架构
6.2.1多媒体架构
- 应用领域

- 系统领域

- 媒体领域

6.2.2多媒体数据库系统
- 多媒体数据管理可以分为多媒体数据库的构造与多媒体数据的存储
- 多媒体数据库相较于文本数据库的特点
- 暂时数据:需要暂存模型
- 大量数据:需要压缩数据
- 数据无直观的信息描述
- 需要预处理
- 新颖的质问机制
- 超媒体:数据的交互能力
6.2.3建立多媒体数据库系统
- 如何建立文本数据库

- 多媒体数据库架构(MMDB) 主要事项
- 实时方面:多媒体数据对象的同时呈现会提高对数据库系统的性能的要求
- 数据共享:传统的数据复制技术无法满足海量的多媒体数据处理,因此数据分享技术是很有必要的
- 多媒体客户端与服务器端的合理架构
- 很多的多媒体应用中,数据存储在远程的站点(如VOD即交互式多媒体视频点播,tele-learning即电话学习),都需要服务器端与客户端的架构
- 客户端包括三个层次:
- 用户交互: 处理用户的输入输出多媒体数据
- 服务器访问: 允许通过客户端搜索获得相关的服务
- 操作系统: 不是多媒体数据库系统真正的一部分
- 服务端包括四个层次:
- 数据库系统界面
- 查询处理
- 文件管理
- 操作系统
- 一个通用的多媒体数据库管理系统架构:

- 简化的多媒体数据库架构模型:

- 详细的多媒体数据库管理系统的架构模型:

- 多媒体数据库管理系统的开发步骤
- 多媒体收集:收集数据,从不同的来源,媒体,如网络、CD、电视等
- 多媒体处理:数据特征提取,包括噪声过滤等
- 多媒体存储:根据应用要求,存储多媒体数据和相应的特征
- 多媒体组织:组织好特征方便检索
- 多媒体查询处理:设计好索引结构,配置好高效的搜索算法
6.2.4多媒体数据库管理系统的软件架构
- 多媒体数据库管理系统(MMDBMS)的软件架构

- 分布式多媒体数据库系统架构

- 视频数据库系统架构

- 端对端保护质量/服务质量管理

- 分布式多媒体数据库管理架构

- 系统概况

6.3多媒体系统服务模型
6.3.1什么是媒体服务/服务器?
- 一个可升级的存储管理器
- 在磁盘实现多媒体数据的最优分配
- 实现内存和基于磁盘的输入输出优化
- 支持
- 实时和非实时的客户端
- 媒体数据的持续显示
- 混合作业:调度程式区块的检索
- 执行认证控制
6.3.2服务模型
- 随机存取
- 通过较小的响应时间,尽可能增大任意时间点能同时接受服务的客户端数量
- 尽可能减少等待时间
- 增强的按次计费(EPPV)
- 保证响应时间的同时,提升能超出有效磁盘和内存带宽的同时接受服务的客户端数量
- 一个例子:服务器有50部电影,每部100分钟。每分钟受到一个播放请求。服务器同一时刻最大可以有20个数据流。
- 随机存储模型:情形一:20个人连上在线播放电影之后,服务器内存所剩无几,第21个得等待80分钟(等第1个放完),第22部电影得等待81分钟…情形二:20个连接之后,没有更多的内存能够分配.第21部电影得等(初始延迟),直到一轮前20部电影每部都连接过
- 按次付费模型:任意时刻有20部电影在下载,每5分钟初始化一次.在这些20分钟中,数据流被均匀分布
6.4多媒体数据存储
- 存储要求
- RAID技术
- 光存储技术
6.4.1多媒体数据要求
* 存储和带宽要求
- 在存储中用字节或兆字节衡量
- 在带宽中用比特/秒或兆比特/秒衡量
一幅图像大小为 480 x 600 (每个像素24比特),
–864k 字节 (无压缩).
–两秒内传送 => 3.456Mb/s.
1GB 硬磁盘
–1.5小时of CD音频 或者
–36秒电视播放质量的视频
–需要800秒传送时间 (10Mbits/s网络).

* 延迟和延迟颤动要求
- 数字音频和视频是时间依存性的媒体
- 动态媒体 ⇒ 实现一种适当质量的音频和视频的播放,媒体样本必须是基于有规律的时间间隔上可以接收和回放的.e.g.
- 音频回放必须达到8K samples/sec.
- 首尾相连的延迟是所有在多媒体系统部分的所有延迟的和, 磁盘存取,ADC, 编码, 主机处理, 网络获取&传输,缓冲,解码以及DAC
- 在大部分会话应用中,首尾相连的延迟应该保持在300ms以下.
- 延迟变动通常称作延迟颤动.它应该足够小来达到顺畅的回放连续的媒体,e.g.
- 对于电话质量的声音和电视质量的视频应该小于10ms
- 对于在高质量的立体效果音频应该小于< 1ms
* 其他要求
- 对语义结构的搜索
- 对文字数字的信息,电脑能够从DB或文档中搜索和检索文字数字的项目.
- 自动检索数字音频、图像和视频是非常难的. 因为没有语义结构被显示出来通过一连串的样本值.
- 在相关媒体中的反交错关系
- 多媒体数据的检索和传输必须是协调和展现的,以便它们指定的时间关系在表现时被保持.
- 一个同步的体系以便确定用来获取要求的同步度的机制.
- 两个工作区域: 用户定向和系统定向同步.
- 错误和丢失偏差
- 与文字数字信息不同,我们可以容忍一些在多媒体里的错误和丢失
- 对于声音,我们能够容忍错误率在0.01.
- 对于图像和视频,我们能容忍错误率在0.0001到0.000001.
- 另外一个参考量:数据包丢失率——一个更加严格的要求.

6.4.2服务质量(QoS)
为了提供统一的构架去指定和保证那些各异的要求,一种叫做服务质量(QoS)的概念被引进来.
- • QoS 是要求的集合,但是并没有普遍接受的一种.
- • QoS 是在多媒体应用中和多媒体系统中一种通过协商同意的一种合约.
- • QoS 的必要条件通常是在两个方面指定的:更可取的质量和可接受的质量.
- • QoS 保障可以是如下三种形式的一种: 可证实的或确定的, 不确定或统计性的以及毫无保障的.
- • 许多研究还在进行.
6.4.3文件系统
文件系统是操作系统中最显而易见的部分.
- • 文件系统的组织
操作系统的可用性和便捷性中非常重要的因素.
- • 文件存储在第二级存储器中,因此它们可以被不同程序使用.
- • 在传统的文件系统中,存储在文件中的信息类型有程序的源文件,项目,函数库,以及目录等等.
- • 在多媒体系统中,存储的信息还包含数字视频和音频以及与它们相关的实时读写要求.
传统文件系统的主要目标:
- • 为文件连接用户提供一个舒适的界面
- • 提高使用存储媒体的效率
- • 允许自由的删除和增添文件
多媒体文件系统的主要目标:
- • 提供一种稳定的和随时间检索的数据.
- • 能过通过对每个数据流的足够的缓冲和对磁盘行程算法的利用实现,特别是对数据的实时存储和检索的最优化.
6.4.4多媒体文件系统
- • 更大的连续媒体文件和这些文件通常被连续的检索是优化磁盘布局的原因.
- • 连续媒体流绝大多数属于ROM,它们在记录的同时很可能也在回放.
- • 因此, 它似乎是合理的在磁盘上存储连续媒体数据形成大的数据区域.
- • 一些很有可能被一起检索的文件在磁盘中被组织在一起.
- • 通过这样的磁盘布局,缓冲的要求和寻找时间减少了.
- • 连续接近的缺点就是在插入和删除数据过程中外部的碎片和拷贝增加.
6.4.5数据管理和硬盘数据跨盘
数据管理:
- • 指令排队技术:通过系统CPU允许执行多序列指令.帮助最小头转换和磁盘旋转延迟.
- • 分散聚拢: 分散是把数据放置在内存和磁盘中可用的最适合区域中的一种进程.聚拢是把数据重组在磁盘和内存中连续的区域.
磁盘数据跨盘:
- • 把多重设备连接到单一本机适配器上.
- • 一种好的增加存储容量的方法是增加增量设备.
6.4.6独立冗余磁盘阵列(RAID,Redundant Arrays of Inexpensive Disks)
根据定义RAID有三个性质:
- • 用户视作磁盘的集合作为一个或多个本地设备.
- • 数据通过预先约定的方式分布在设备中.
- • 冗余的容量和重组数据容量增加,为了在磁盘毁坏后恢复数据.
RAID的目标:
- • 迅速备份磁盘系统.
- • 以的花费构建大容量存储.
- • 以的花费拥有更高的性能.
- • 数据容易恢复.
- • 高的MTBF (mean time between failure).
6.4.7不同级别的RAID
八种不同性能的RAID:
- • Level 0 - 磁盘数据分段
- • Level 1 - 磁盘镜像
- • Level 2 - 带海明码校验
- • Level 3 - 带奇偶校验码的并行传送
- • Level 4 - 带奇偶校验码的独立磁盘结构
- • Level 5 - 分布式奇偶校验的独立磁盘结构
- • Level 6 - 两种存储的奇偶校验码的磁盘结构
- • Level 7 - 优化的高速数据传送磁盘结构
以521字节为一组分布在设备中的数据叫做分段.多个分段组成数据块.
RAID 0:无差错控制的带区组
- • 为提高表现将磁盘读写重叠
- • 多驱动器连接到一个磁盘控制器
- • 数据被分割成1~64Kb的片段分散到多个磁盘上
- • 磁盘分段提供更高的数据读写速度
- • 典型应用:数据库应用
- • 缺点:
- 如果一个驱动器损坏,整个驱动系统崩溃
- 不提供数据冗余,0容错率
RAID 1:镜象结构
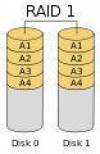
- • 每个驱动器拥有一个镜像驱动
- • 每个文件的两个备份将被写到两个驱动器
完全 冗余
- • 性能
- 磁盘写:花费两倍的时间
- 磁盘读:可以通过叠加搜索提速
- • 典型应用
- 文件服务器提供备份以防磁盘损坏
- • 双工运行
- 使用两个控制器
- 第二个控制提高容错率和表现
- 分离的控制器允许并行读取和并行写入
RAID2:带海明码校验
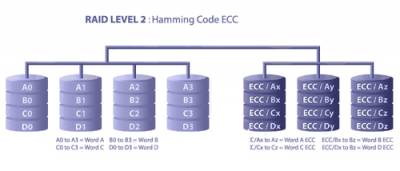
- • 包含连接到一个磁盘序列控制器的多磁盘序列
- • 数据被交错写入多驱动器(经常一次一字节)多检测磁盘用于检测并纠正错误
- • 海明码校验(HEC)代码用于错误检测和纠正
- • 所有磁盘轴必须被同步作为一个访问所有磁盘的I/O操作
- • 好处:
- 高水准的数据整合度和可靠性(纠错特性)
- 主要用于超级计算机的使用少量I/O请求访问大量数据
- • 缺点:
- 昂贵-需要多驱动器作为错误检测及纠正
- 纠错方式-缓慢且繁琐
- 多媒体应用可以承受偶然丢失的字节或者对系统和显示质量没有显著影响
- 一个磁盘上的每个扇都和其他磁盘扇联系形成一个一个单独的存储单元,这需要多个数据磁盘上的多个扇来存储仅仅几byte,造成存储浪费
- 当每个事务的数据大小很小的时候,不能被用来进行事务处理
RAID3:带奇偶校验码的并行传送
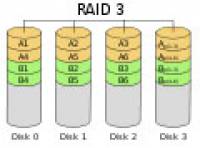
RAID 3是使用了奇偶校验的并行传送技术。RAID 3以并行方式存放数据,校验码在写入数据时产生并保存在另一个磁盘上。需要实现时用户必须要有三个以上的驱动器,读写速率很高,因为校验位比较少,因此计算时间相对比较少。只提供查错而没有纠错功能。适合需要大量IO的设备。
RAID4:带奇偶校验码的独立磁盘结构
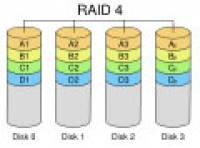
RAID 4是带奇偶校验码的独立磁盘结构。RAID 4有与RAID3类似之处,不同之处在于它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。而RAID 3则是一次一个区块。它的特点和RAID 3类似。数据恢复比RAID 3困难。适合应用于高IO需求,不适合高数据传输率需求的设备。
RAID5:分布式奇偶校验的独立磁盘结构

RAID 5是采用分布式奇偶校验的独立磁盘结构。RAID 5与RAID 4的组织方式相似,但是避免了RAID 4中的瓶颈。RAID 5的奇偶校验码存在于所有磁盘上,读出效率很高,写入效率一般,块式的集体访问效率较高。因为奇偶校验码在不同的磁盘上,所以提高了可靠性,允许单个磁盘出错。适合应用于具有大量随机的IO访问,而较少有大块数据的设备。
RAID6:两种存储的奇偶校验码的磁盘结构
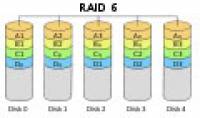
RAID 6是采用两种存储的奇偶校验码的磁盘结构。在纠错能力上对RAID 5进行的改进,数据更可靠
RAID7:优化的高速数据传送磁盘结构
RAID 7是优化的高速数据传送磁盘结构。RAID7所有的I/O传送均是同步进行的,可以分别控制,这样提高了系统的并行性,每个磁盘都带有高速缓冲存储器,实时操作系统可以使用任何实时操作芯片,达到不同实时系统的需要。具有很高的数据访问效率。
6.4.8数据存储
数据存储采用的策略依靠存储技术,存储设计和数据本身的特性. 任何存储都有以下几个特征:
- – 存储容量
- – 数据读写的标准操作
- – 数据读写的传递单元
- – 存储单元的物理构造
- – 读写头,每张磁盘的柱面数,柱面的轨道数,轨道上的扇区数
- – 读入时间和寻找时间
作为电脑外围设备的存储技术, 光学媒质是多媒体环境中最流行的.
6.5 多媒体系统应用
6.5.1多媒体系统应用链
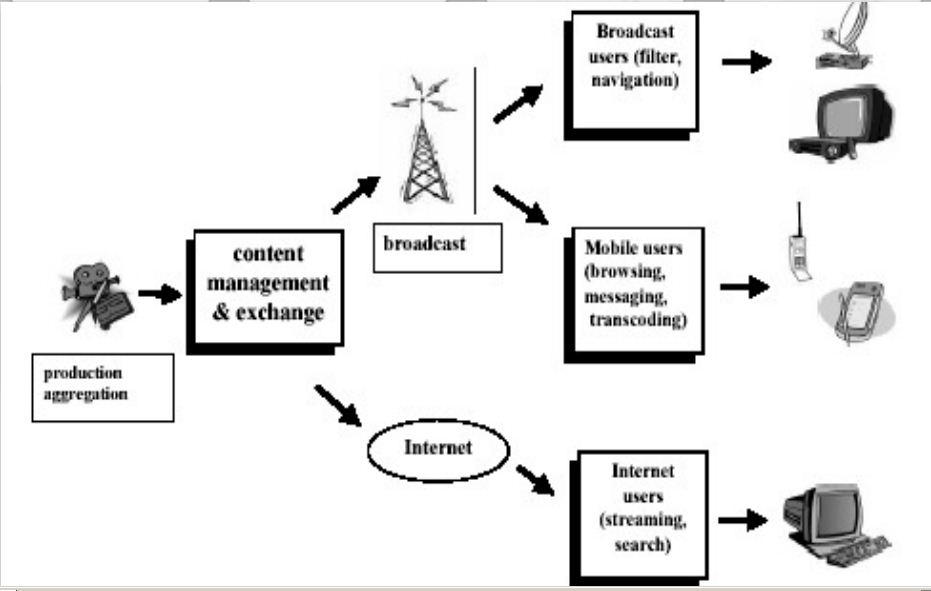
多媒体可以被广泛地运用到广播系统和网络系统.广播系统的广播用户如航海航空,移动用户;网络系统里如网民。如图:
6.5.2多媒体应用
- 应用范围、产业和用法:
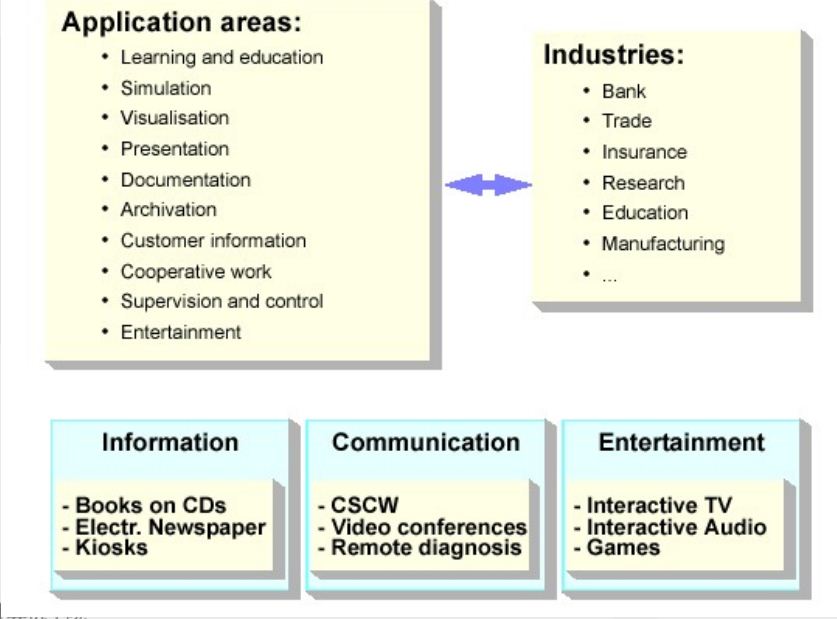
- 应用分类:本地(local)
分布式(distributed)
- 基础的多媒体服务:
- 人际沟通
- 信息检索
- 信息记录和编辑
- 应用举例:超媒体课件、视频会议、视频点播、互动电视、家庭购物、游戏、数字视频编辑和制作系统…