NameClarifier: 对论文作者姓名进行消歧的可视分析系统
作者:lujunhua 日期:2016 年 11 月 1 日
没有评论
论文:NameClarifier: A Visual Analytics System for Author Name Disambiguation
作者:Qiaomu Shen, Tongshuang Wu, Haiyan Yang, Yanhong Wu, Huamin Qu, and Weiwei Cui
发表:VAST2016 / TVCG
一、概述
目的: 不同文献中的作者重名问题
动机:
- 现有的纯挖掘算法往往采用全局模型, 无法处理一些特殊情况 (比如, 同一篇文章重名; 重名者研究领域高度相似; 重名者研究领域随时间发生变化等等)
- 现有可视化方法很少
贡献:
- 用可视化方法将原本黑盒解法变成一个白盒的过程
- 提供一种引导用户进行分类的方法而不是简单的给出分类结果
- 提出一种两步去重的过程, 迭代的改良分类结果
二、系统流程
给定一个名字, 输入到这里的是所有这个名字的文献的资料Pre-processor: 对每个publication抽取metadata 给Analyzer然后Analyzer首先将所有有明确身份的文章分组(person1, person2等等以及各自对应的文章的集合), 将剩下的标为歧义的文章. 然后将确定的组与歧义的文章比较估计相似性, 利用的是不同时间所发表刊物的一些属性和共同作者的一些数学关系最后Visualizer展现这些关系, 一共有三个view 第一个view主要是分类那些有着歧义名的文章来到现有的确定组中去, 后面两个view主要是来验证前面的初步结论.
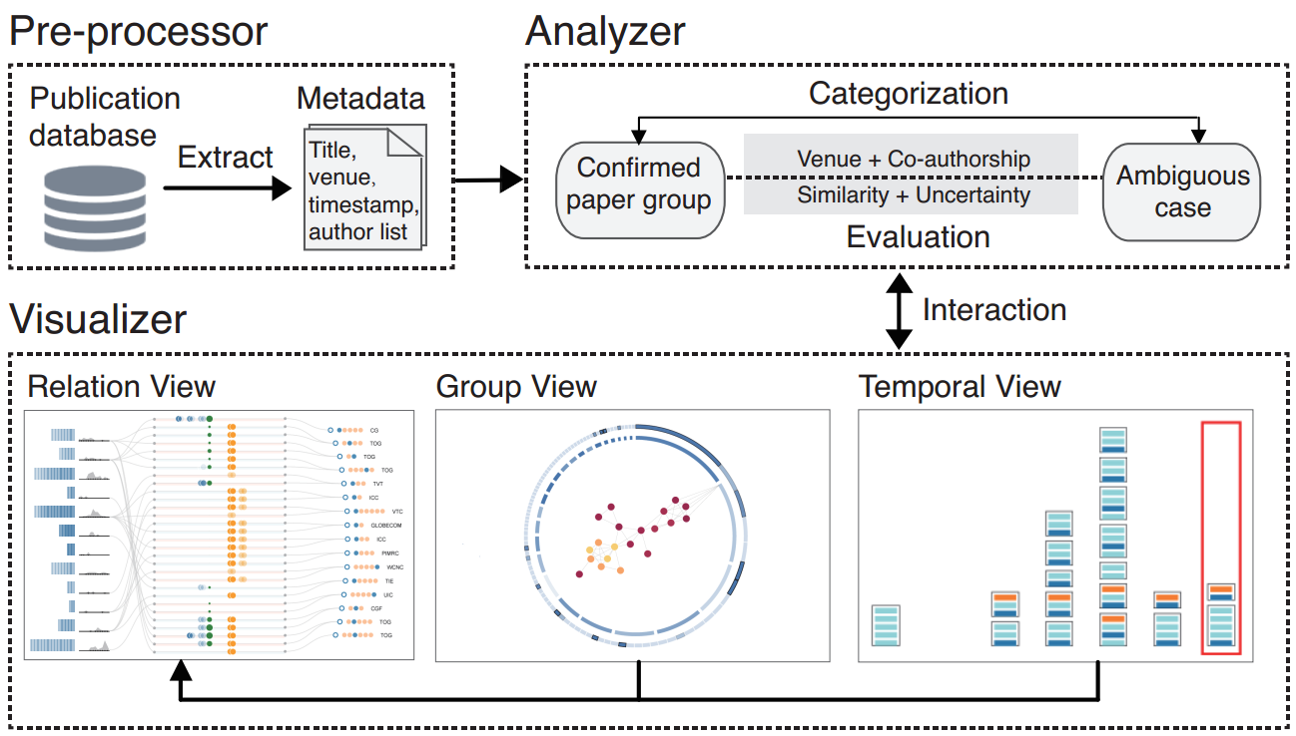
系统流程
三、数据处理