MNSS: Neural Supersampling Framework for Real-Time Rendering on Mobile Devices
IEEE Transactions on Visualization and Computer Graphics, 2023 (Accepted)
Sipeng Yang, Yunlu Zhao, Yuzhe Luo, He Wang, Hongyu Sun, Chen Li, Binghuang Cai, and Xiaogang Jin
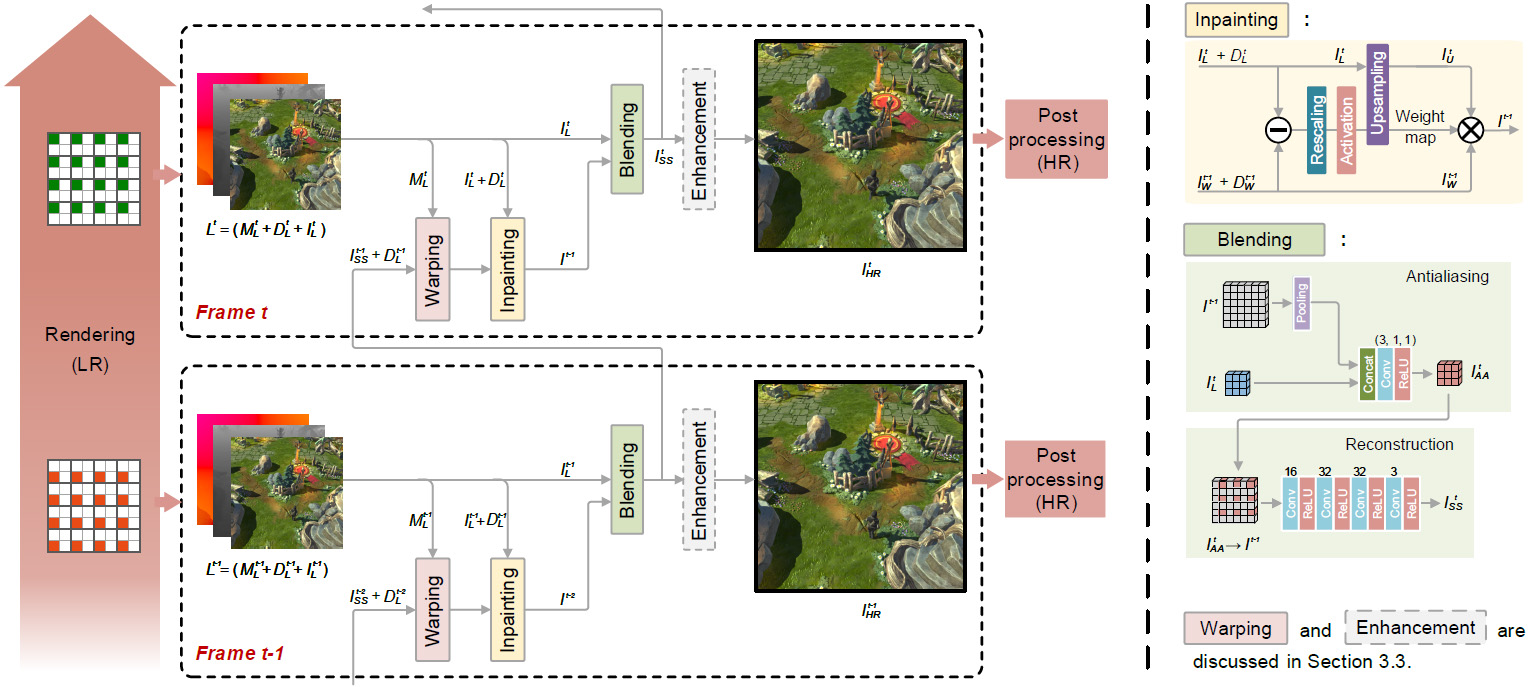
Overview of our proposed neural supersampling framework. The left shows the pipeline of the method, and the right shows the architecture of sub-networks. For current Frame t, we first render the LR data Lt by adding a viewport sub-pixel offset to the camera. Then, the previous reconstructed frame It−1SS and its depth map Dt−1L are loaded and reprojected to align to the current frame using the motion information MtL, following which a weight map is generated by inpainting module to fill in invalid history pixels. After that, the current frame ItL and the repaired history frame It−1 are fed into the blending network to generate HR output ItSS. In addition, the enhancement module can be optionally active by the user to sharpen edges. Lastly, the reconstructed frame is pulled through the post-processing stage of the rendering pipeline.
Abstract
Although neural
supersampling has achieved great success in various applications for
improving image quality, it is still difficult to apply it to a wide range
of real-time rendering applications due to the high computational power
demand. Most existing methods are computationally expensive and require
high-performance hardware, preventing their use on platforms with limited
hardware, such as smartphones. To this end, we propose a new supersampling
framework for real-time rendering applications to reconstruct a high-quality
image out of a low-resolution one, which is sufficiently lightweight to run
on smartphones within a real-time budget. Our model takes as input the
renderer-generated low resolution content and produces high resolution and
anti-aliased results. To maximize sampling efficiency, we propose using an
alternate sub-pixel sample pattern during the rasterization process. This
allows us to create a relatively small reconstruction model while
maintaining high image quality. By accumulating new samples into a
high-resolution history buffer, an efficient history check and re-usage
scheme is introduced to improve temporal stability. To our knowledge, this
is the first research in pushing real-time neural supersampling on mobile
devices. Due to the absence of training data, we present a new dataset
containing 57 training and test sequences from three game scenes.
Furthermore, based on the rendered motion vectors and a visual perception
study, we introduce a new metric called inter-frame structural similarity
(IF-SSIM) to quantitatively measure the temporal stability of rendered
videos. Extensive evaluations demonstrate that our supersampling model
outperforms existing or alternative solutions in both performance and
temporal stability.