
该工作围绕“如何在同一生成框架中同时满足语义可控性与时空精确约束”这一核心问题展开,提出通过多层级条件引导机制,将文本提供的高层语义信息与关键帧提供的局部时空约束进行解耦建模与统一融合,从而实现既符合语义表达、又严格满足关键帧约束的高质量人体运动生成。
研究背景
文本驱动人体运动生成近年来成为计算机动画与虚拟人领域的重要研究方向。相比传统关键帧动画方式,文本能够提供更加自然和灵活的语义控制,使用户可以通过语言直接描述动作意图。然而,文本本身缺乏精确的时间与空间约束表达能力,难以明确指定动作发生的具体时刻、轨迹变化以及局部姿态细节,从而导致生成运动在复杂场景中容易出现语义偏移或空间不稳定的问题。
另一方面,关键帧作为传统动画制作中的核心控制手段,能够在特定时间点提供精确的姿态与空间约束,有效提升运动的可控性与物理合理性。但关键帧本身不具备语义表达能力,如果仅依赖关键帧进行动画生成,则往往需要大量人工标注才能完整描述一个动作过程,极大增加了创作成本。因此,如何在统一模型中同时利用文本的语义表达能力与关键帧的精确控制能力,实现低成本、高精度的运动生成与编辑,是当前领域中的关键挑战。
现有方法虽然已经尝试将关键帧或空间约束引入扩散模型进行条件控制,但通常仍存在两个核心问题:一是文本语义与关键帧约束之间缺乏有效对齐机制,导致生成过程出现冗余动作或时序错位;二是关键帧通常被作为软约束处理,难以在生成过程中实现严格的空间一致性,从而影响动画的物理真实性与视觉稳定性。
研究创新与突破
针对上述问题,该研究提出了一种多级扩散生成框架,通过在扩散模型内部引入“全局语义引导 + 局部关键帧引导”的双层控制结构,实现文本语义与关键帧时空约束的统一建模。在生成过程中,全局引导机制将文本语义与关键帧序列的整体结构信息进行融合,并通过跨注意力机制注入扩散U-Net主干网络,从而对整体动作类别与时间结构进行统一调制;局部引导机制则在每个关键帧邻域对运动进行细粒度约束,使生成结果能够在关键时间点严格对齐指定姿态,同时保证非约束区域的自然过渡与运动连续性。进一步,为提升关键帧约束的严格性,该研究在推理阶段引入轨迹修正与扩散补全相结合的精细化控制策略,通过对根节点轨迹进行基于速度分配的自适应误差修正,消除全局空间漂移,同时利用掩码驱动的姿态回填机制实现关键帧的硬约束对齐。在此基础上,针对交互式运动编辑任务,该方法进一步设计了基于DDIM反演的语义保持编辑策略,通过将原始运动映射至扩散潜空间,并结合固定点迭代与关键帧约束重采样,实现了在局部编辑条件下对原始运动语义结构的最大程度保留,从而支持高保真、可控的人体运动生成与编辑。综上,该研究作出以下贡献:
一种多级扩散生成框架,通过统一建模文本语义与关键帧时空约束,实现了高层语义控制与低层精细约束的协同运动生成机制,有效提升了运动的可控性与一致性。
一种全局与局部结合的多级条件引导机制,其中全局引导融合文本语义与关键帧序列结构信息以调制整体运动动态,局部引导则对关键帧邻域运动进行细粒度约束,从而同时保证语义一致性与空间精度。
一种无需额外训练的语义保持运动编辑方法,通过DDIM反演与固定点迭代机制,在满足新增关键帧约束的同时最大程度保留原始运动语义,实现高保真交互式运动编辑能力。
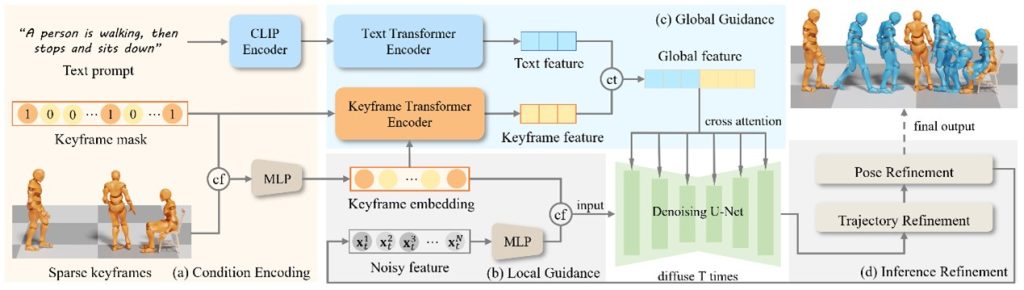
本方法系统框架示意图
研究成果
下面介绍本方法生成的结果以及与现有方法的对比。通过定性与定量实验,分别与现有方法(OmniControl、CondMDI 和 MaskControl)进行比较。
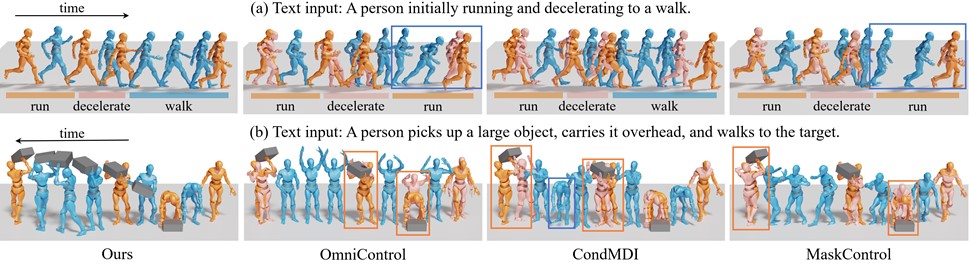
图中展示了不同方法在文本条件运动补间任务上的定性对比结果。可以看到,现有方法在多阶段动作(如“跑步—减速—行走”)以及物体交互场景中,普遍存在时序错位、姿态不稳定以及关键帧偏移等问题。相比之下,本方法能够严格满足关键帧约束,同时保持动作语义一致性与过渡自然性,在复杂场景下表现出更稳定的时空控制能力与更高的生成质量。

上表展示了不同方法在HumanML3D数据集上的定量比较结果。可以看到,本方法在整体指标上均取得更优表现。在关键帧控制方面实现严格对齐,在语义一致性指标上取得更高得分,同时在运动质量与物理合理性指标(Skating Ratio、Jitter)上均优于所有基线方法,表明该方法能够在保证高精度空间约束的同时维持更自然的运动分布与更稳定的时序结构。
本研究由浙江大学计算机辅助设计与图形系统全国重点实验室金小刚教授担任通讯作者,博士研究生武琳峻为本文的第一作者。本研究受到了浙江省重点研发计划项目和国家自然科学基金的资助,与腾讯天美工作室开展合作完成。
