ACM SIGGRAPH 2024于7月28日在美国科罗拉多州丹佛市召开,这是全球计算机图形学与交互技术领域最高水平的学术盛会,被中国计算机学会CCF推荐为A类会议。本次大会邀请到NVIDIA CEO黄世勋、Meta CEO扎克伯格等做主题演讲。会议期间,浙江大学计算机辅助设计与图形系统全国重点实验室周昆教授获颁时间检验奖(Test-of-Time Award),实验室十余项最新成果进行口头报告。

会议召开第一天,ACM SIGGRAPH 2024时间检验奖评奖委员会主席Sylvain Paris博士为周昆教授团队颁发了获奖证书。该奖项颁发给发表十年以上对计算机图形学和交互技术产生重大且持续影响的论文。本年度评选范围涵盖了2012至2014年期间在 ACM SIGGRAPH上发表的论文。周昆教授团队2013年的研究工作“3D Shape Regression for Real-Time Facial Animation”获此殊荣,这也是亚洲团队首次获得该奖项。评奖委员会评价该工作“提出了一种使用单目RGB摄像头进行实时、精确三维人脸跟踪和运动捕捉的开创性方法,为在移动设备上创建逼真的面部动画开辟了一条途径”。
会议期间,浙江大学计算机辅助设计与图形系统全国重点实验室共有十余篇论文进行了口头报告。这些研究成果内容丰富,涉及人工智能内容生成(AIGC)、三维视觉(3D Vision)、数字人、神经渲染与高斯渲染、物理仿真、图像处理等领域。具体如下:
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
Wenqi Dong, Bangbang Yang, Lin Ma, Xiao Liu, Liyuan Cui, Hujun Bao, Yuewen Ma, Zhaopeng Cui

论文提出了一种三维可控的物体生成框架Coin3D,它可以让用户以手工搭积木般先构建一个粗糙模型,进而实现从三维上直接控制生成3D模型的大致外观轮廓。基于这一设计,论文还提出了一种新颖的交互式生成工作流,允许用户在单次生成好物体后,对局部纹理或者几何进行生成式编辑,且不影响其余部分的几何与纹理,同时可在数秒内实现快速预览。最后,论文提出了一种基于体素的得分蒸馏采样方法,有效提升最终导出的带纹理网格的重建质量。
DreamMat: High-quality PBR Material Generation with Geometry- and Light-aware Diffusion Models
Yuqing Zhang, Yuan Liu, Zhiyu Xie, Lei Yang, Zhongyuan Liu, Mengzhou Yang, Runze Zhang, Qilong Kou, Cheng Lin, Wenping Wang, Xiaogang Jin

DreamMat可以根据文本描述为给定三维模型生成高质量PBR材质,解决了之前方法生成纹理中残留光影信息的问题。论文微调了一个可感知光照的新型二维扩散模型,使其产生与环境光照条件一致的图片。通过在材质生成中应用该扩散模型以及已知的环境光,DreamMat生成的PBR材质不仅与几何形状相匹配,且反照率贴图无内嵌光影效果。广泛实验表明,此方法生成的PBR材质具有更佳视觉吸引力,并显著提升渲染质量,适合游戏和电影制作等下游任务。
MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
Shangzhan Zhang, Sida Peng, Tao Xu, Yuanbo Yang, Tianrun Chen, Nan Xue, Yujun Shen, Hujun Bao, Ruizhen Hu, Xiaowei Zhou

论文提出了一种新颖的材质生成方法,通过文本描述为三维网格模型生成高分辨率、高真实感的材质。该方法包括部件控制的图像生成和材质图优化,并利用紧凑的材质图谱库,支持多种网格类别的高质量材质生成。实验结果显示,该方法在真实感和效率上较现有方法有显著提升,极大简化了三维内容创建中的材质生成和编辑过程。
DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation
Chong Zeng, Yue Dong, Pieter Peers, Youkang Kong, Hongzhi Wu, Xin Tong

论文介绍了一种在文本驱动图像生成中实现精细光照控制的新方法。现有扩散模型虽能生成任意光照下的图像,但常将内容与光照关联,且文本提示难以描述详细光照。为此,本研究通过辐射提示增强文本提示,引导模型生成特定光照下的图像。本研究提出三阶段方法:首先,用预训练模型生成临时图像;其次,用DiLightNet模型结合辐射提示重新合成前景物体;最后,调整背景光照与前景一致。该方法在多种文本和光照条件下验证有效。
RTG-SLAM: Real-time 3D Reconstruction at Scale Using Gaussian Splatting
Zhexi Peng, Tianjia Shao, Liu Yong, Jingke Zhou, Yin Yang, Jingdong Wang, Kun Zhou

论文提出了一个使用高斯表达对大规模场景进行实时三维重建的系统。该系统具有紧凑的高斯表达,将高斯根据不透明度分为两类,一类用于拟合表面和主要颜色,而另一类用于拟合残差颜色。并且提出了一种新的深度渲染方法,使单个不透明高斯能够很好地拟合局部表面。此外,论文还提出了一种高效的高斯优化方法,大大减少了计算成本。与同期先进方法相比,该系统速度约为其两倍,内存成本减半,并且在多个指标上表现出色。
X-SLAM: Scalable Dense SLAM for Task-aware Optimization using CSFD
Zhexi Peng, Yin Yang, Tianjia Shao, Chenfanfu Jiang, Kun Zhou

论文提出了X-SLAM,一种实时可微分的稠密SLAM系统,该系统利用复步有限差分方法高效计算数值导数,从而避免了对大规模计算图的需求。论文的关键在于将SLAM视为一个可微分函数,通过在复数域内的泰勒展开来计算重要SLAM参数的微分,并将其与不同的下游任务结合实现任务感知的优化。并且还可以计算高阶导数。基于X-SLAM,为相机重定位和机器人主动扫描两个重要任务设计了优化框架,结果表明论文的优化显著地提升了任务表现。
High-quality Surface Reconstruction using Gaussian Surfels
Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, Weiwei Xu

3DGS方法渲染质量较高但在几何重建上精度较低。针对此问题,论文提出了高斯Surfel的概念,通过将3D高斯椭球在Z方向压扁上为2D椭圆以贴合物体几何表面,设计了自监督的“法向-深度一致性”与“法向先验”损失项为法向的优化提供梯度。论文同时提出体积过滤方法去除深度融合中的漂浮点,通过泊松重建得到高质量的几何表面。高斯Surfel在几何重建质量和速度上均大幅度优于3DGS和其最新的改进方法。
GaussianPrediction: Dynamic 3D Gaussian Prediction for Motion Extrapolation and Free View Synthesis
Boming Zhao, Yuan Li, Ziyu Sun, Lin Zeng, Yujun Shen, Rui Ma, Yinda Zhang, Hujun Bao, Zhaopeng Cui
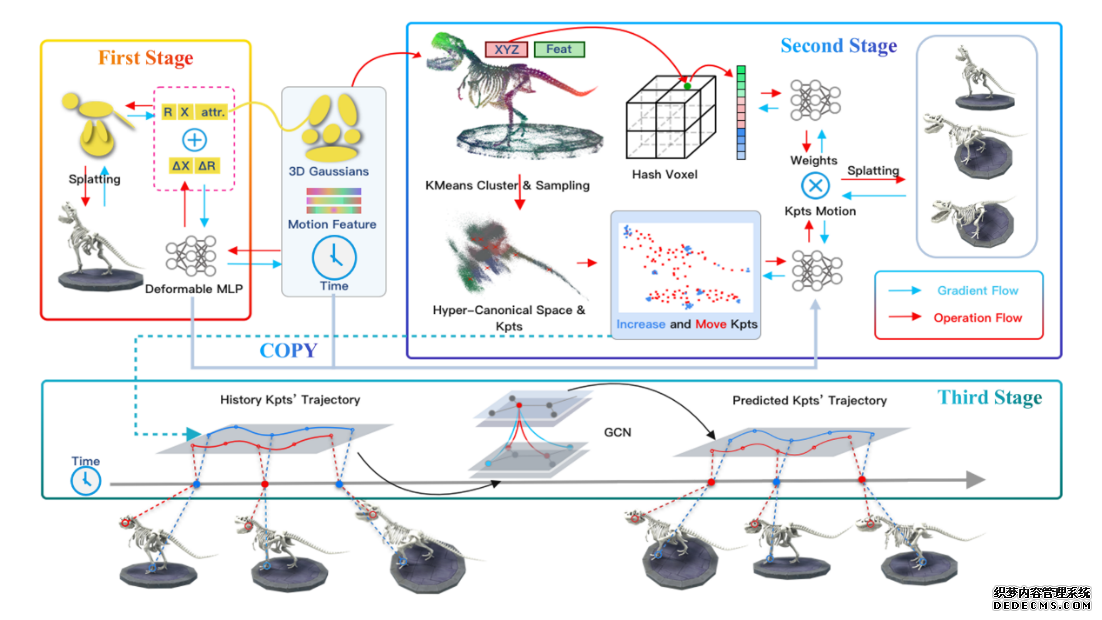
在动态环境中预测未来场景对于智能决策和导航至关重要,这是计算机视觉和机器人技术尚未完全实现的挑战。视频预测和新视图合成等传统方法要么缺乏从任意视点进行预测的能力,要么缺乏在时域上预测的能力。本研究提出了一种新颖的框架GaussianPrediction,它利用动态场景的视频观察重建动态场景,并能从任何视点预测未来状态。本研究的框架在合成和现实世界数据集上都表现出色,证明了其在预测和渲染未来环境方面的有效性。
Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Yiqian Wu, Hao Xu, Xiangjun Tang, Xien Chen, Siyu Tang, Zhebin Zhang, Chen Li, Xiaogang Jin

论文提出了Portrait3D,这是一种新颖的神经渲染文本到三维肖像生成框架,采用几何-外观联合先验,克服了现有方法的Janus、过度饱和和过度平滑问题。论文训练了3DPortraitGAN-Pyramid作为先验,并在其内集成了一种金字塔形三维表示,以减轻“网格状”伪影。在生成过程中,随机图像被投影到隐空间,生成的隐码用于合成金字塔形三维表示。论文使用得分蒸馏采样和扩散模型优化此三维表示,并使用精细化的肖像图像消除结果中的不真实颜色和伪影,从而得到高质量三维肖像。
3D Gaussian Blendshapes for Head Avatar Animation
Shengjie Ma, Yanlin Weng, Tianjia Shao, Kun Zhou
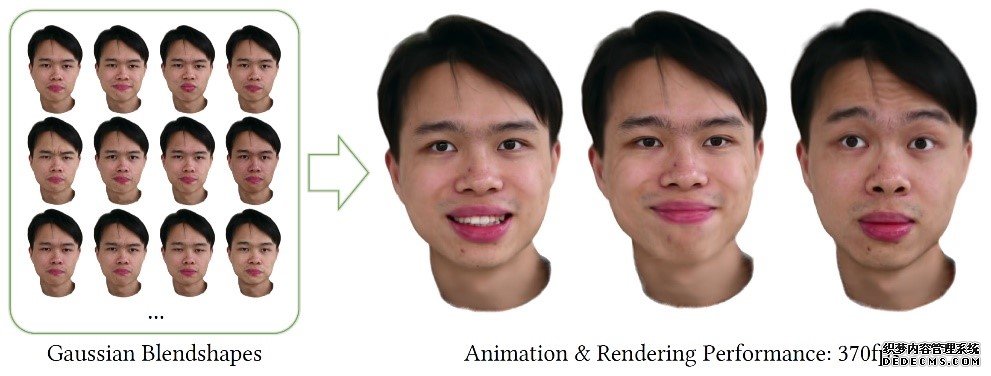
论文提出了3D高斯混合形状表达用于生成逼真的人体头部动画。以单目视频作为输入,论文学习一个中性模型以及一组表情混合形状,对应于经典参数化面部模型中的基础表情。中性模型和表情混合形状都表示为3D高斯,包含一些属性来描绘头部外观。任意表情的人体头部模型可以用表情系数线性混合中性模型和表情混合形状来高效地生成。与目前最先进方法相比,论文的高斯混合形状表达更好地捕捉了视频中的高频细节,并实现了更优的渲染性能(370fps)。
LightFormer: Light-Oriented Global Neural Rendering in Dynamic Scene
Haocheng Ren, Yuchi Huo, Yifan Peng, Hongtao Sheng, Weidong Xue, Hongxiang Huang, Jingzhen Lan, Rui Wang, Hujun Bao

近年来,神经渲染技术利用神经网络表示场景照明并解码最终光辐射,展现出巨大潜力。然而,将物体参数整合进表示可能限制其在完全动态场景中的效果。本文引入“LightFormer”的神经渲染方法,能够实时生成包括动态光照、材质、摄像机和动画对象在内的逼真全局照明。灵感来自多光源方法,重点是场景中光源的神经表示,而非整个场景,从而提高了泛化能力,突破了动态几何场景神经绘制的难题。
3D Gaussian Splatting with Deferred Reflection
Keyang Ye, Qiming Hou, Kun Zhou

基于神经网络和高斯的辐射场方法在新视角合成领域取得了巨大成功。然而,镜面反射依然是一个难题。论文提出了一种延迟着色方法,利用3DGS有效渲染镜面反射。其中最大的挑战来自基于环境光照图的反射模型,它依赖准确的表面法向。论文延迟着色生成的像素级别反射的梯度来联系相邻高斯的优化,使得正确的法向逐渐传播并最终扩展到所有反射物体。本方法在合成高质量镜面反射效果上显著优于其他最新方法,同时运行帧率几乎与原始3DGS方法相同。
Neural-Assisted Homogenization of Yarn-Level Cloth
Xudong Feng, Huaming Wang, Yin Yang, Weiwei Xu

由纱线编织而成的服装面料应力-应变关系复杂,其形变的快速物理仿真计算量巨大,但现有的材质均匀化模型在较大的时间步长下数值稳定性不佳。论文提出了采用神经网络表达纱线织物的均匀化本构模型,在训练神经网络时引入三阶导数和泛化性正则化约束有效提升了数值仿真的稳定性。均匀化神经网络使用纱线级仿真收集的应变能数据集进行训练,定性和定量实验标明,使用神经网络均匀化模型可有效增大时间步长,实现两个数量级的加速。
Mob-FGSR: Frame Generation and Super Resolution for Mobile Real-Time Rendering
Sipeng Yang, Qingchuan Zhu, Junhao Zhuge, Qiang Qiu, Chen Li, Yuzhong Yan, Huihui Xu, Ling-Qi Yan, Xiaogang Jin
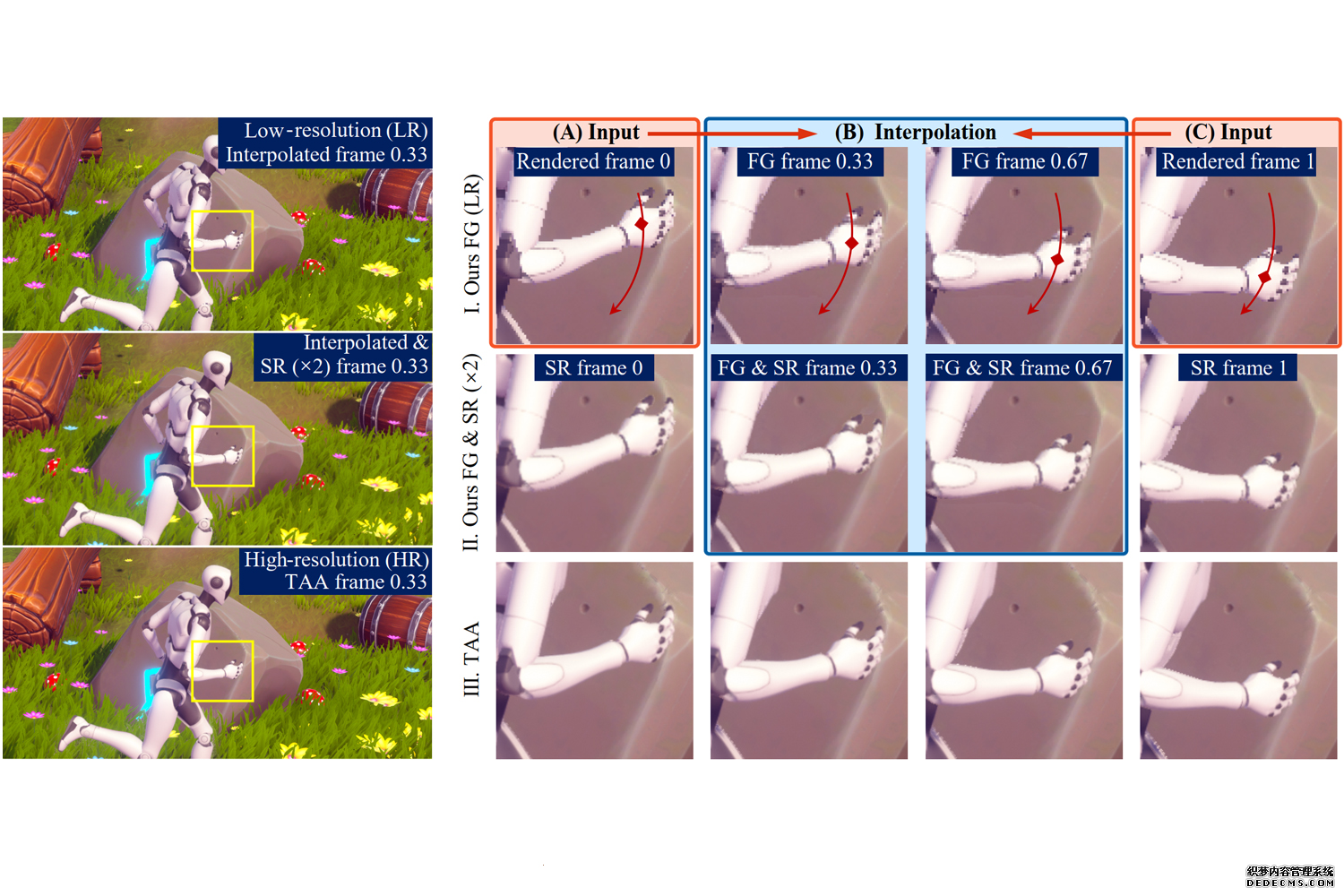
论文提出了一套专为移动端硬件设计的轻量级超采样框架,整合了帧生成与超分辨率技术,能显著提升移动端实时渲染表现。该框架的核心贡献为准确的运动矢量重建方法,无需高端GPU即可实现任意时间的像素运动估计。此外,框架提供的内插帧、外插帧以及相应的超分辨率版本,为用户带来了多样化的选择。实验表明,该框架在移动设备上运行迅速,能生成高质量结果,为超采样技术在多样化硬件环境中的广泛应用提供实证支持。
